折磨了半年,EventHouse 终于要发布了,按照惯例,有些思考写在发布之前。本篇文章不含任何 AI 生成内容。
早在 2024 年 6 月,EventBridge 就已经进行过一次关于 AI 数据的探索。当时瞄准的场景是类似 unstructured 这样的 RAG 数据同步,只是加了 “多源” 这个卖点。但由于产品能力太吃市场,这个单点 Data 能力沉寂了很久很久都没有找到自己的“钉子”。(源自一句话:拿着锤子找钉子)。整个产品的架构逻辑如下:
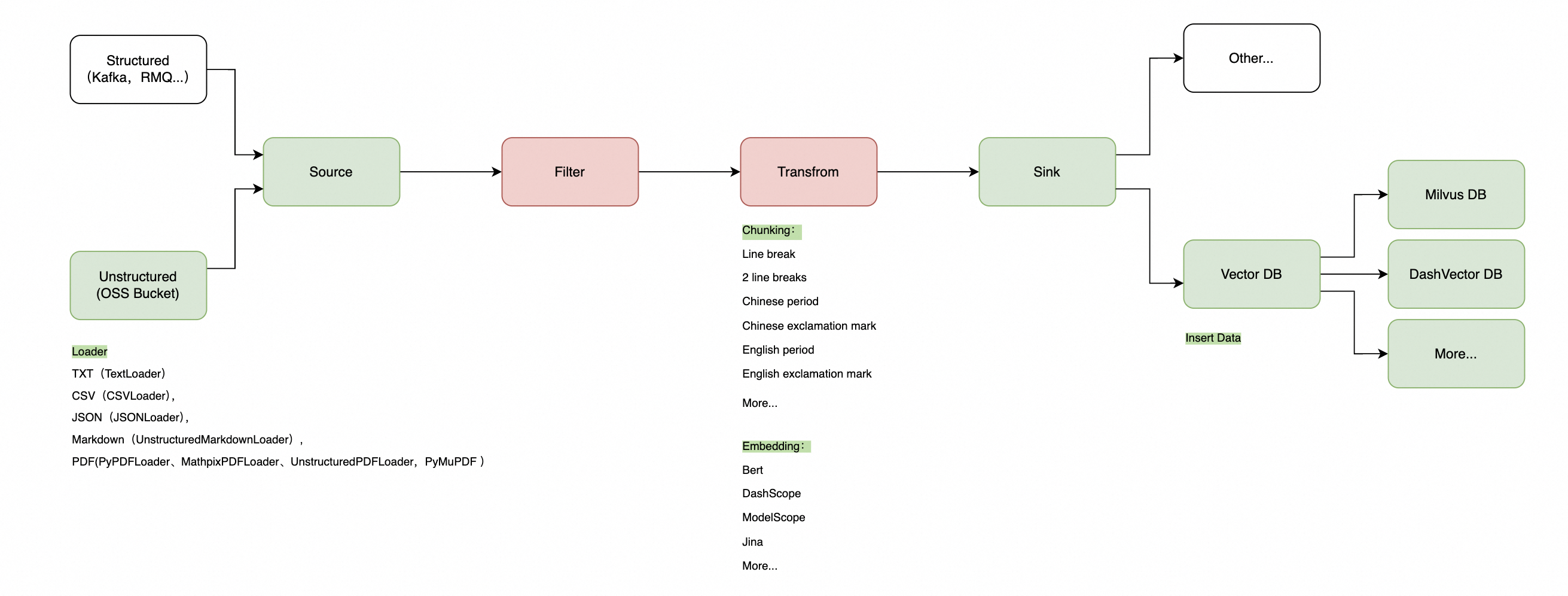
坦白讲,这次产品更新让我最大的感官是 AI 时代,大家都不知道怎么做,也没有什么固定的经典架构可讲。产品侧只需要把最直接的产品功能给客户,端到端的完善整个能力即可,千万不要想着客户会自己补充自己的 组件进来。
这个我接触 Data AI 的开始。
一个急需解决的 AI 数据场景
在 25 年云栖大会的前期,我和我的搭档(For 研发领域的伙伴)两人进行了无数次头脑风暴,彼此脑海里逐渐有个直觉是“现有的数据工具根本无法在 AI 领域直接使用,用户一定需要一整套完整的 Data 方案来与 Agent 结合”。但当时其实我们也只有直觉,抱着这个萌芽,我毅然推去了全部与之无关的工作,开始琢磨这里的“数据工具”到底是什么。
首先,根据第一性原则来思考,在 AI 领域的“数据”到底是什么? —— 我们对这个问题的答案是 “上下文”。
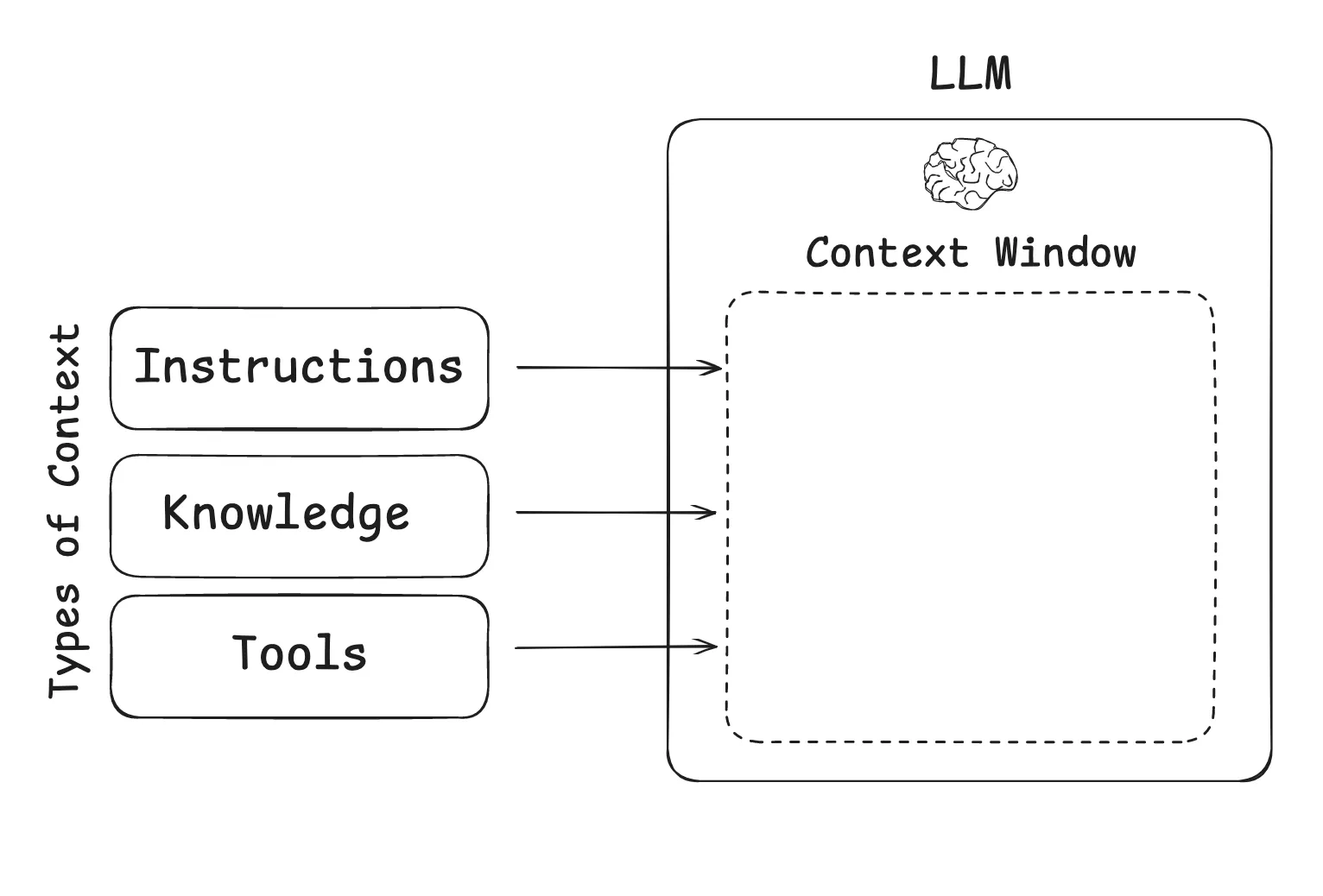
什么是上下文工程呢?举个例子,LLM 就像一个新型的操作系统,LLM 就像是 CPU,而上下文窗口就像 RAM。与 RAM 一样,上下文窗口处理各种上下文的容量有限,正如操作系统会筛选适合 CPU 的RAM 内容一样,上下文工程也扮演着类似筛选合适内容给到大模型这样的角色。下文工程是一种系统性方法,旨在于AI 生成前为模型构建完整的信息环境。该方法以上下文而非训练的方法达到模型输出优化的效果,论点在于模型输出质量更多取决于所提供的丰富上下文,而非模型架构本身。
上下文工程是传统提示工程的升级。上下文工程扩展至多层信息,包括系统提示(如“你是技术写手,语气需正式且精确”),还可加入外部数据,如检索文档(AI 主动从知识库获取信息)、工具输出(如调用API 查询日程),以及用户身份、历史交互、环境状态等隐性数据。
就此,我们有了第一个比较核心的目标 “企业在 AI 领域的 Data 其实就是 构建 Agent 的上下文”。诚然,上下文一定是由多种数据源共同组成的,譬如 Chat Message,Documents/Email 还有包括存在各个组件中的譬如 MySQL,Kakfka 等数据。
有了这个认知,自然就会关注到 模型上下文协议(MCP) ,在之前的博客中有讲到 MCP ,感兴趣的同学可以考考古 《关于 MCP 协议的一些零散记录》。
从 EventBridge 数据集成的产品特性出发,我们大致整理出这样一个模糊的概念:
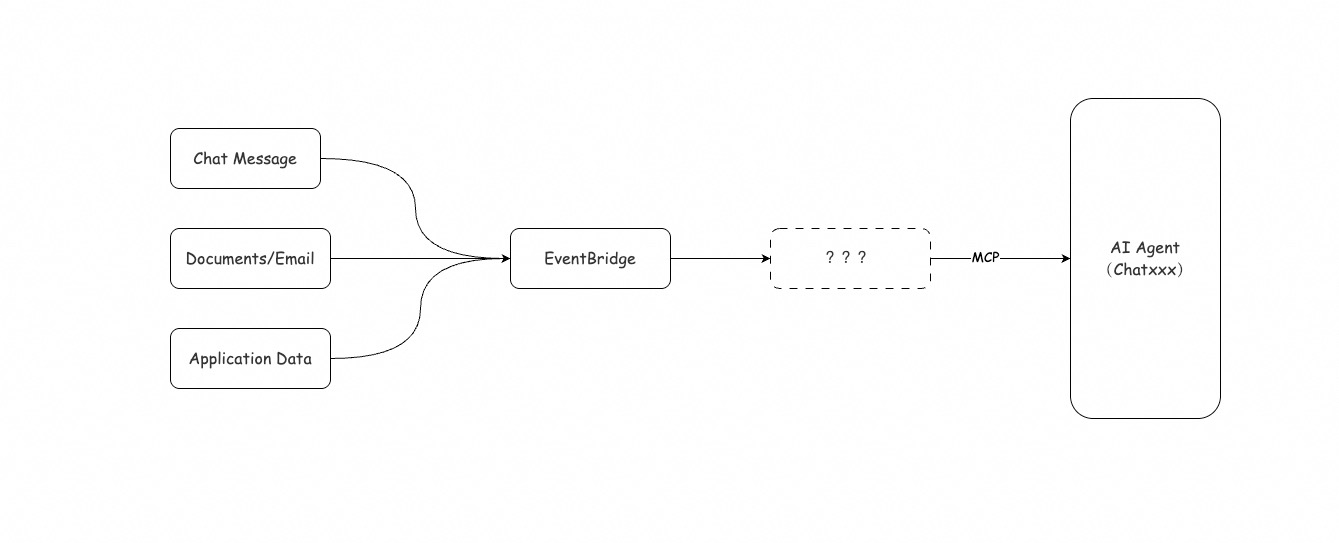
这个产品架构解决的最核心的用户痛点是:如何把企业用户里的真实数据喂给大模型。
有了这个最终目标似乎一切都清晰了起来,我们想做的其实就是 企业数据 Data > Agent 这样的桥接。
最原始的工程实践
当意识到我们想做的东西似乎很少有人踏足时(只是当时以为),我们的第一反应是兴奋,然后就开始了漫长的竞品调研和 Paper 阅读。在 langchain 和 manus 开放的上下文工程实践中(具体链接可至文末的参考资料查看),我们意识到目前上下文限制导致目前的 Agent 工程实践对数据这块的处理非常局促,将实时数据全部导入给模型不是那么现实。以 Qwen3 max 为例,模型支持的最大上下文长度是 256kb。
所以无论是针对企业数据还是长/短期记忆现阶段在给 Agnet 数据时需要一个完整的数据检索能力,通常情况下非结构化数据是通过向量检索的方式也就是 RAG,结构化数据的方案很多有 SQL 检索也有图检索。
于是,我们调研视角又关注到了又一个领域就是数据在最早时的工程实践 ChatBI/NL2SQL,如下是一个比较经典 ChatBI 架构:
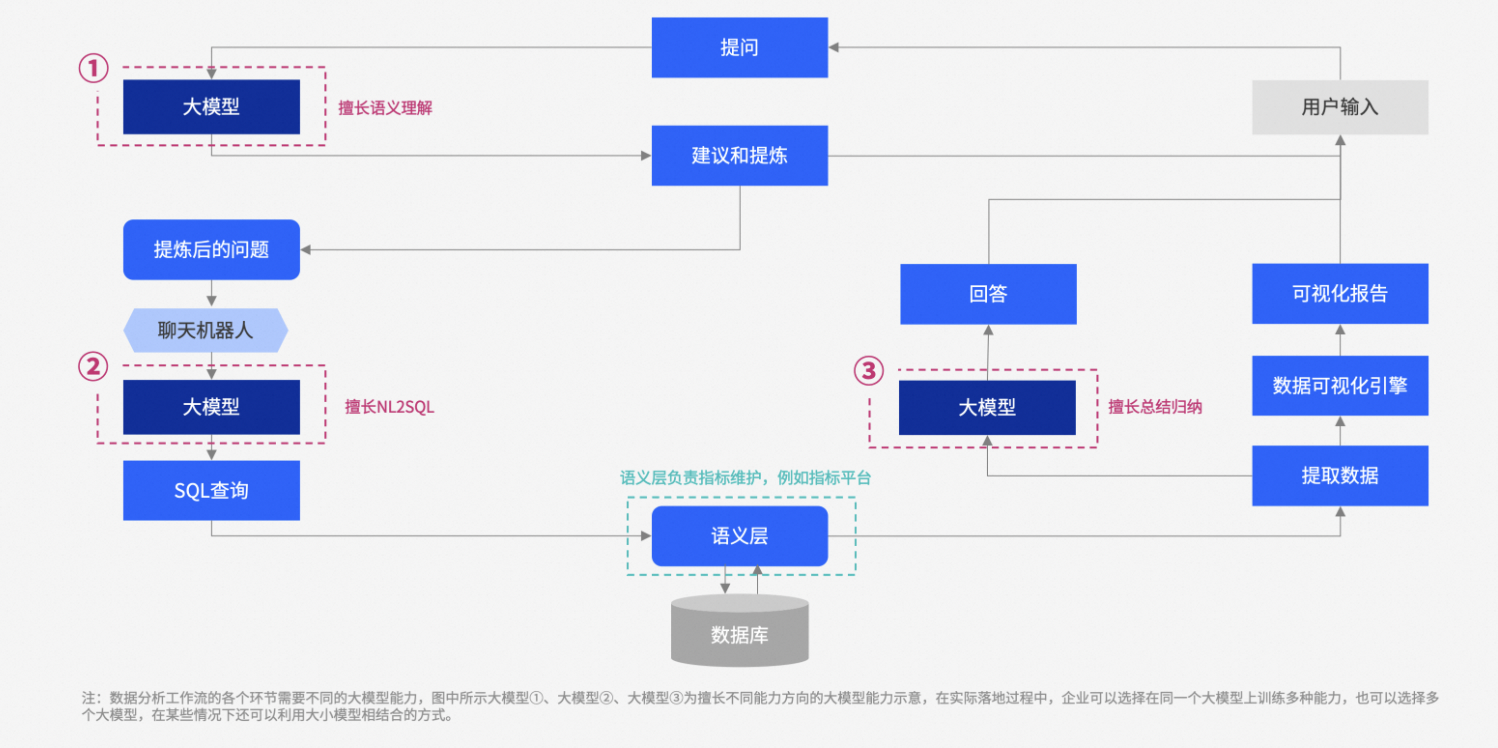
ChatBI 主要解决的问题就是如何生成 SQL 来读取数据,其核心是将用户的自然语言查询转换为可执行的 SQL 语句(即 NL2SQL),从而实现数据分析于数据查询。值得注意的是 ChatBI 返回的 SQL 生成的可视化报告不会经过大模型处理,将直接反馈给客户。
NL2SQL 通过将自然语言查询转化为数据库操作语言,降低了数据访问的门槛。使得非技术人员可以直接以自然语言提问,从而访问和分析数据。这不仅提高了业务决策的速度和灵活性,还促进了数据驱动文化的建立。因此,被视为企业探索 AI 技术的一个“敲门砖”,帮助企业实现快速的数据洞察和决策支持。
至此,对 Agent 这块的核心交互基础算是有了,可以借鉴 NL2SQL 方法论,引导客户通过执行 SQL 检索的方法将企业数据透出给 Agent。
完整的工程闭环
按照这个思路,我们逐渐扩充和讨论端到端的产品形态,最终 EventHouse 的整体产品设计也终于出来了。这个设计吸取了之前 RAG 方案未端到端闭环的缺陷,提供了一个较为完整的使用路径,整个产品架构如下:
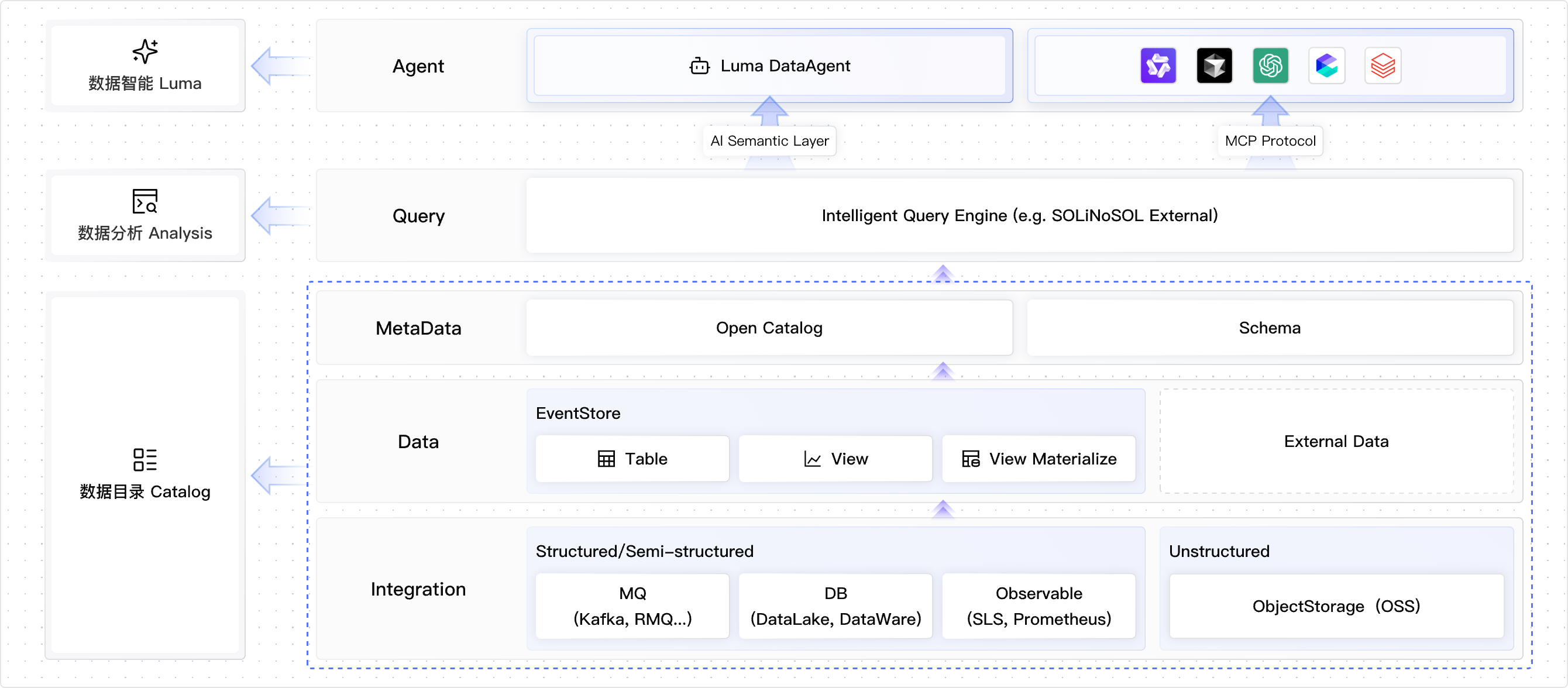
EventHouse 的核心架构采用分层解耦的设计,清晰地划分为集成层、数据层、元数据层、数据查询与数据智能层。每一层都由特定的核心组件支撑,共同构成了一个强大的数据处理与分析闭环。同时每个层级都相对独立,可拆分使用或者一站式端到端使用。
集成层(Integration)是整个系统的入口,它如同一个多功能的翻译官,能够无缝对接包括 Kafka、RocketMQ 在内的多种消息队列,以及 MySQL 等关系型数据库和 对象存储OSS,实现了对全模态数据的统一接入 。这确保了无论数据最初以何种形式产生,都能进入 EventHouse 进行统一处理。
数据层(Data)的核心是 EventStore,它是一种专门为事件流设计的存储格式。与通用的文件存储不同,EventStore 针对 JSON 等事件数据进行了专用的列式压缩,能够显著降低存储成本,据称较传统数据库可节省50%以上 。更重要的是,它提供了类似关系型数据库的表(Table)、视图(View)甚至物化视图(Materialized View)等抽象,使得分析师可以用熟悉的 SQL 语法进行复杂查询,同时又保留了数据湖的扩展性。Data 另一个核心是支持外部数据的引入即 ZeroETL,通过“外部表”的概念将 SQL 执行下推到端侧,从而显著较少数据转储成本。
元数据(MetaData)层是连接异构数据源的桥梁,也是实现统一治理的关键。采用兼容 Hive Metastore Thrift API 标准 的Open Catalog。EventHouse 能够自动发现并注册来自不同源头的数据元信息,如 Kafka Topic、RDS 表结构等 。当上游数据模式发生变化时,Catalog 还能管理兼容性的 Schema 演进,避免下游分析任务因模式不匹配而中断。同时,它能自动追踪事件从产生到分析的全链路血缘,极大地简化了故障排查和影响评估 计算与智能层由 Intelligent Query Engine 主导,它解决了传统数仓无法处理高并发实时事件,而传统消息队列又缺乏复杂关联分析能力的根本矛盾 。此外,它还支持联邦查询(Federated Query)布,允许企业直接在 EventHouse 中通过SQL JOIN操作,将内部存储的表与外部的数据源(如OSS上的日志文件或另一个RDS数据库中的维表)进行联合分析,无需进行任何数据物理搬迁 。
最后,数据智能层(Agent)是 EventHouse 最具前瞻性的部分,它通过引入自研的 Luma Agent ,将 AI 能力深度融入数据平台。这一层的目标是实现“对话即分析”,最终迈向“自主分析”。用户不再需要编写复杂的 SQL 或等待报表生成,而是可以直接用自然语言提问,并获得即时的回答。更进一步,内置的 Luma DataAgent 能够像人类专家一样,主动监控数据、发现问题、规划分析路径并执行查询,最终输出带有根因分析和行动建议的完整报告 。这标志着数据分析范式的深刻变革,从被动响应转向主动洞察。同时,企业自建的 Agent 也可以引用 EventHosue 开放的 MCP 端点对数据进行查询和获取。
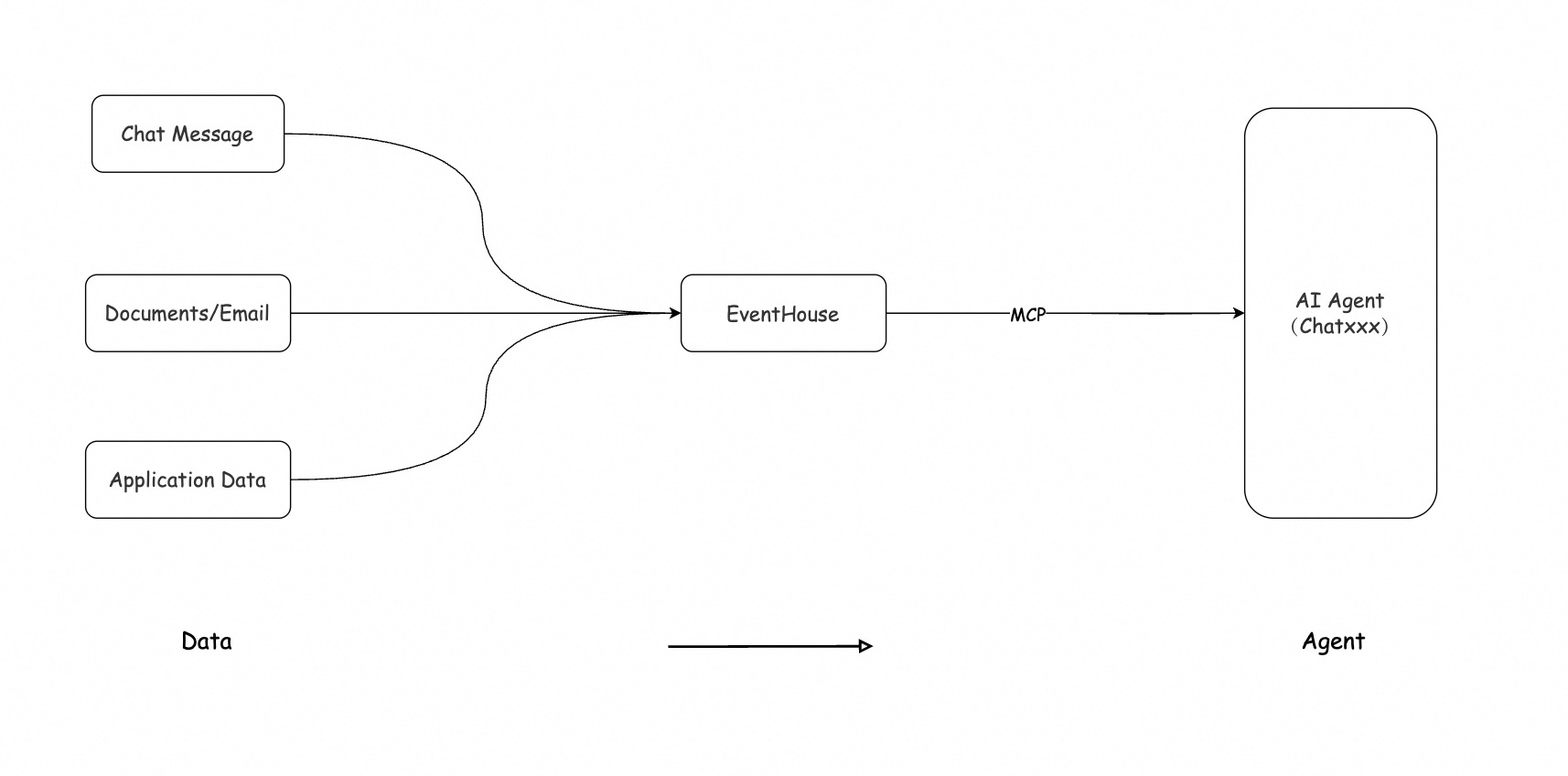
我们借助这套架构完整闭环了 企业数据 > Agent 的 Bridge ;值得强调的是 EventHouse 并非一个孤立的存储或者检索引擎,而是一个由多个解耦层组成的完整 DataAgent 体系,在架构中每个层级都可以单独拆分使用,旨在构建一个真正面向未来的数据平台。
我们正在邀请测,如果有兴趣可以在这里申请测试:
https://survey.aliyun.com/apps/zhiliao/CxmEbmixU
更多参考资料:
https://blog.langchain.com/context-engineering-for-agents/
https://manus.im/zh-cn/blog/Context-Engineering-for-AI-Agents-Lessons-from-Building-Manus