云栖大会结束了,看着自己做的产品重磅发布,心中有种莫名的释然感。有个一直以来都保留的习惯,当负责的某个产品正式上线时,总想将一些心得也好,想法也好,或者单纯对这款产品的期许也好。写下来,记录下来。
也是由于工作太忙,已经很久没有写博客,索性趁着这次发布一吐为快。
什么是工作流?
这次发布的产品全称其实是云工作流(CloudFlow),准确来讲是一款 Tool 类型的工具产品。比较诚实的讲,它其实并不是新东西,开源上有 AirFlow,DolphinScheduler ,n8n 的珠玉在前,公共云服务上有 AWS Step Function, Azure Logic Apps 怀璧在后。坦白讲这确实不是一门好生意,在做最初的市场分析时,林林总总的十几款竞品让我着实心灰意冷了一把。
但这些都是后话了,摆在面前的首要问题是理清楚工作流到底是什么。
工作流的广泛定义:工作流其实最早始于制造业,相关概念包括作业车间和排队系统(马尔可夫链)。最早在工业领域定义的“工作流管理”用于指与价值链中的信息流而不是物质货物流相关的任务;他们将信息的定义、分析和管理描述为“工作流管理”。最早的工业工作流试图通过对制造流程进行分析来提高工业制作效率,以减少浪费和进行标准化生产。
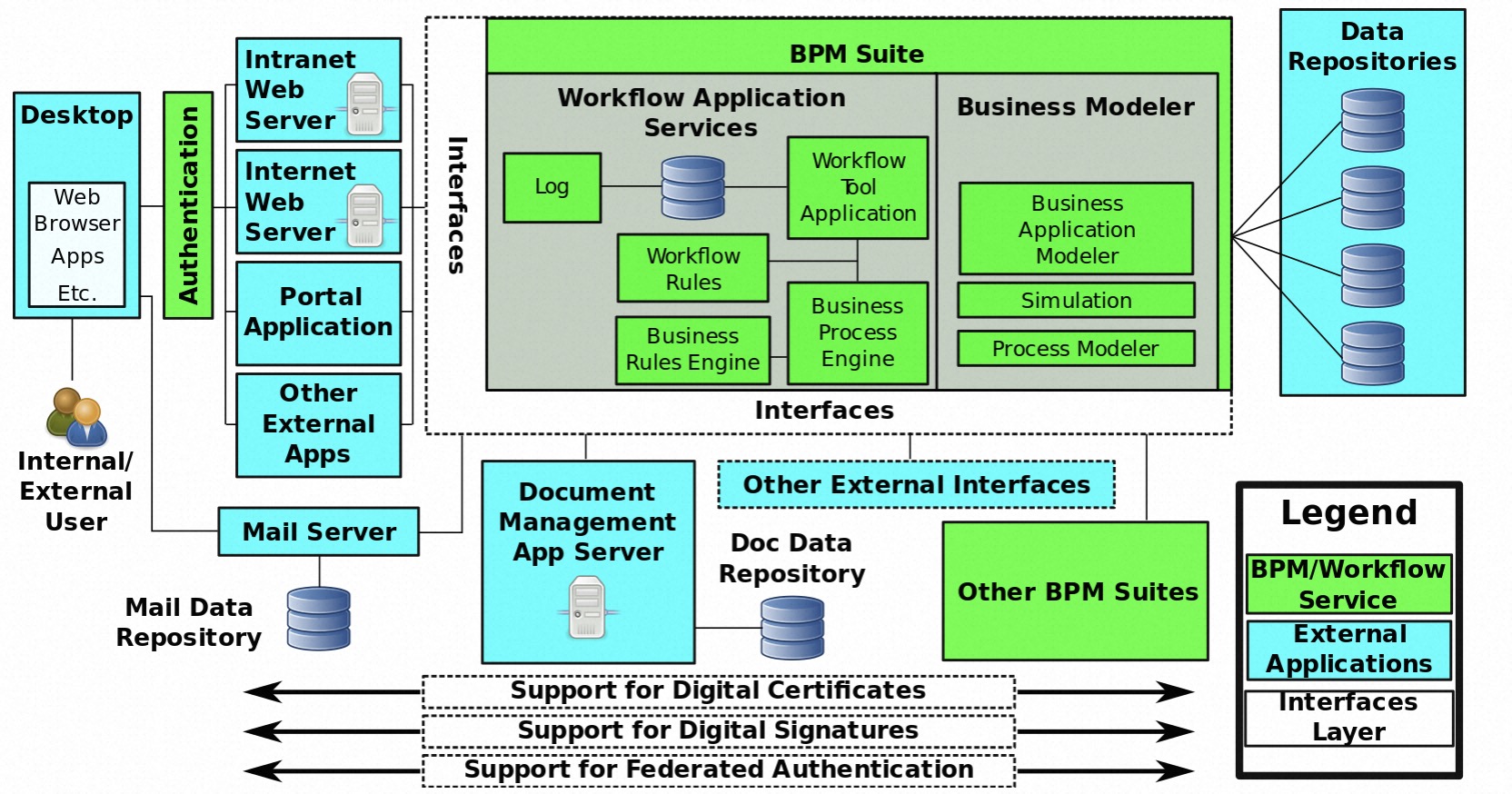
工作流在信息系统的定义:在面向信息系统服务的体系结构中,应用程序可以通过可执行工作流来表示,其中不同的服务组件在工作流管理系统的控制下进行交互以提供相应的功能。工作流的典型特征是简单性和可重复性,通常用图表或流程列表来可视化。下图是一份典型的业务流程建模;
工作流的实现?
了解完工作流的定义,我们再来看工作流的实现形式;通常情况下,工作流实现方案有 DAG,StateMachine
DAG:即 Directed acyclic graph,如下图有向无环图指的是一个无回路的有向图。目前的 AirFlow 等开源项目主推的工作流实现方案。DAG 的描述和他的名字一样,缺陷在于不支持有环的任务流转(这一点只是为了简化,实际上也有办法实现)
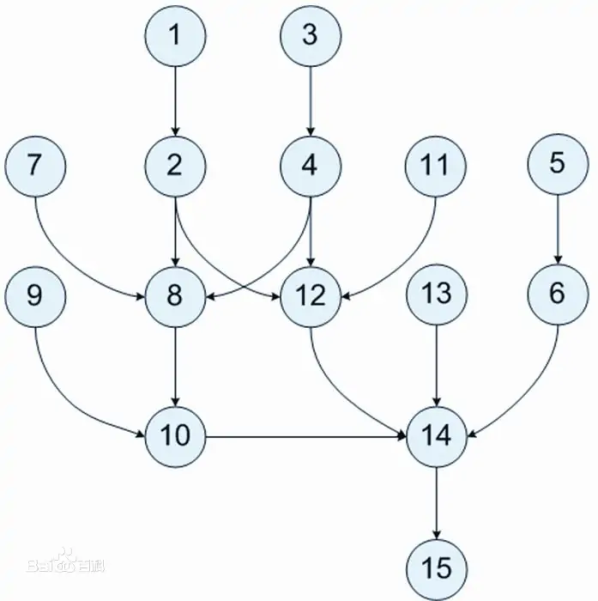
DAG 定义演示:
TaskA:
Actions:
– 动作 A
Dependencies:
TaskB:
Actions:
– 动作 B
Dependencies:
– TaskA
TaskC:
Actions:
– 动作 C
Dependencies:
– TaskA
– TaskB
对这个 dag 进行简单的拓扑排序,就能得到他大概的执行流程, 下图为依赖图,首先会执行 TaskA,然后 TaskB,最后 TaskC:
graph LR
TaskA–>TaskB
TaskA–>TaskC
TaskB–>TaskC
伪代码实现:
For task in Tasks:
if all_done(task’s Dependencies):
do(task)
FSM/SM:即 Finite-State Machine/StateMachine,状态机/有限状态机;状态机的基本组成要素是状态和流转。通过状态和流转来确定流程的具体走向及流程数据。下图是一个经典的状态机 coin-operated turnstile 案例,通过不同的状态和流转实现不同的结果输出。
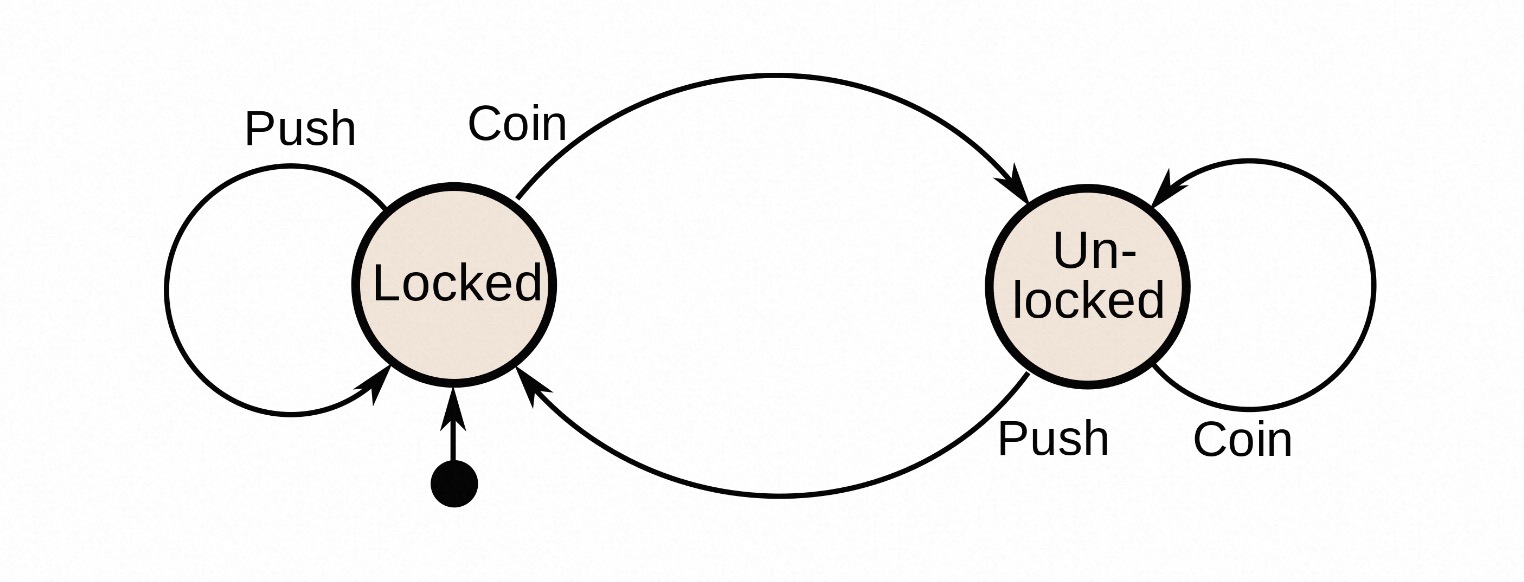

状态机是实现任务流的另一种形式,表达的核心在于描述任务流转行为,即上述的转换
同样,我们来举个例子
Start: TaskATaskA:Actions:– 动作ANext:TaskBTaskB:Actions:– 动作BNext:TaskCTaskC:Actions:– 动作CNext:End
graph LR
Start–>TaskA
TaskA–>TaskB
TaskB–>TaskC
TaskC–>End
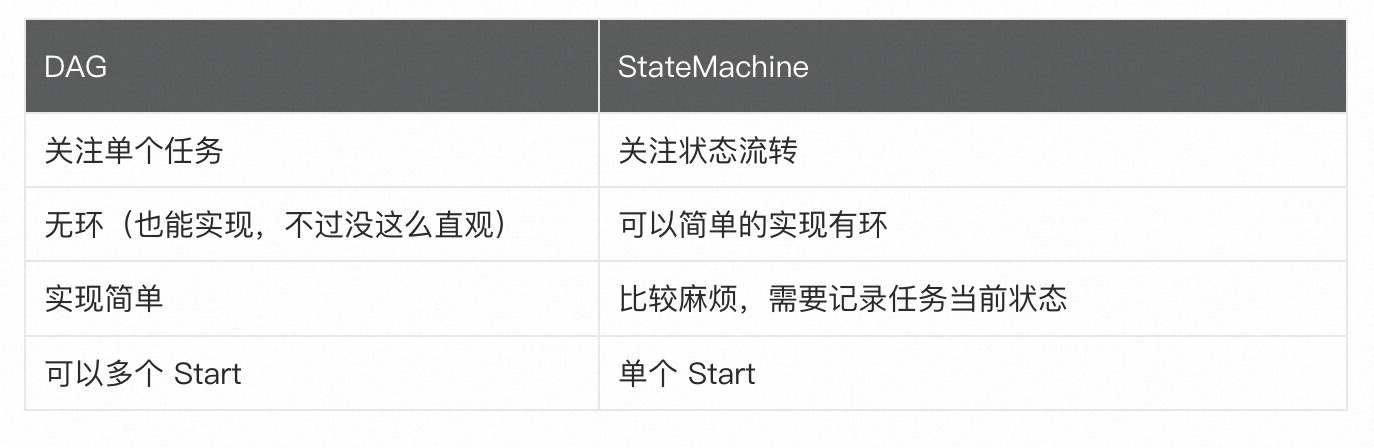
实现对比
灵活性
当任务一个接一个地执行时,DAG 是顺序模式。StateMachine 的下一步只有在前一步完成后才会开始。例如,只有律师签字后,老板才会在文件上签字。DAG 本质上似乎是僵化的和确定性的。相反,StateMachine 是异步工作;由于流程中的步骤是由某些事件/操作触发的,因此不一定要按严格的顺序执行。从这个角度来看,StateMachine 更加灵活。
然而,一旦公司有了新的业务需求,情况就会发生变化。想象一个 StateMachine,它具有以下三种状态:提交申请、接受申请和拒绝申请。目前,我们可以看到三个独立的状态以及向它们的流转方向。后来决定添加一些新状态,例如更改应用并要求的实时反馈。在这种情况下,StateMachine 的数量以及它们之间的转换次数会大大增加。此外,在添加新的 State 时,将无法在不破坏其余状态的情况下更改其中任何一个状态。因此,大部分情况下会发现自己不是简单地添加新功能,而是从头开始构建新系统。
易懂
StateMachine 乍一看似乎很容易使用。开发人员只需要按照业务流程绘制一个图表,在该图表上描述特定的状态和事件,这些状态和事件将触发其余 State 的转换。然而,状态机的主要问题是在实践中它只适合具有一维问题的业务,当业务逐渐复杂时,即使使用 StateMachine 系统也将很快就会变得难以管理。
可读性
状态机模型似乎可读性更高,因为 DAG 关注描述任务,一眼很难看出任务流转的模式,状态机直接描述任务流转,内部就可以很明显的看出每个 Stage。事实并非总是如此。想象一个任务流程有几百个任务, 这种情况下,即使是任务流所在的领域,比如 CRM 领域的专家也很难读懂整个任务流,这时候阅读当个任务的动作或者依赖,变成了一种更为简单直观的方式,通过好的前端实现,DAG 的可读性至少不会比 状态机差。
工作流实现结论
如果系统不是很复杂,StateMachine 和 DAG 其实在实现领域会各有优劣,目前 AWS 是 StateMachine 的忠实簇拥,此次业内 CNCF 也推出了 Serverless Workflow 这样的基于StateMachine 的实现定义。趋势来看,目前选择 StateMachine 会比选择 DAG 风险更小。
阿里云 CloudFlow 的前世与今生
云工作流(CloudFlow) 其实是在最近一个月临近发布确定的新名称,之前有个更通俗的定义是 FNF(函数工作流),它之前只是为函数量身打造的状态机管理工具。为了做好云内集成,从更上层的产品纬度增加用户用云的粘性,在 23 年 S1 结束的时候,这款存在了很久,已经似乎被淡忘的产品迎来了它新的使命 —— 做整个阿里云生态的集成编排。
当 CloudFLow 这个名字定下来的时候,我似乎诚惶诚恐,一方面是因为它的产品边界,另一方面对它的市场定位及客群产生质疑。当下,场景不够垂直,用户不明确的产品必死无疑。
所以,我们大致对这款产品做了一个初步的定义:
客群:CloudFlow 服务的群体是业务开发/数据开发人员,与其他低代码产品不同,非运营/营销/销售等非技术人员。
场景:CloudFLow 定位是开发效能提升工具,主要解决的问题是复杂业务场景下的开发效能问题。通过可视化/可组装等特性的显著降低业务开发代码量,提升开发效能。其中,收益最多的是在云上业务领域的开发,通过预置的流程组件和模块,显著降低代码开发量。
基于如上描述,我们大致定义出一个 CloudFlow 的产品架构
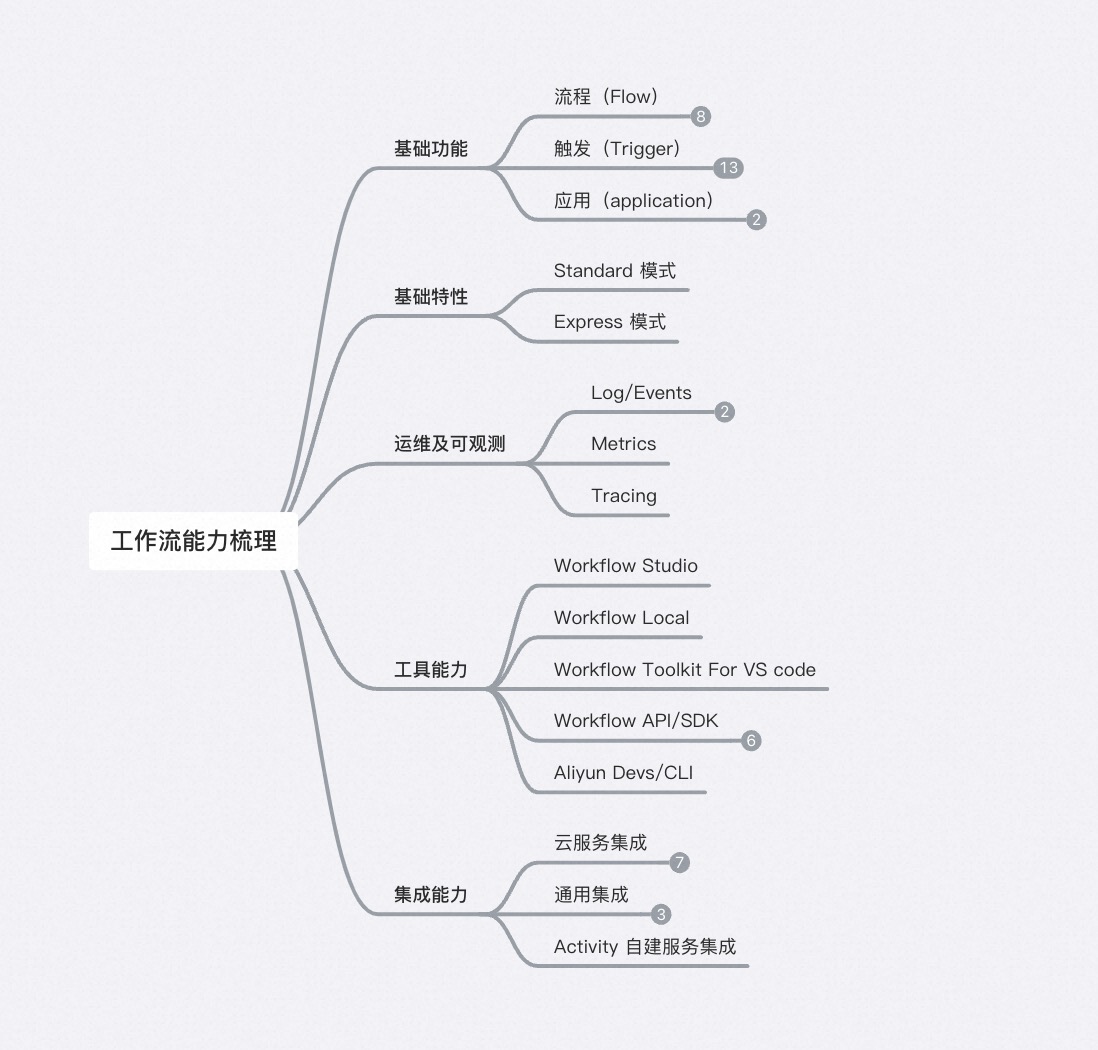
以及对应的最佳实践,大致思路是以 APIGW,EB 等产品作为流程触发管道,并通过 CloudFlow 来编排具体业务。

大概就分享这么多了,后续有更多见解会持续更新博客。
最后打个广告,欢迎试用呀
https://www.aliyun.com/product/aliware/fnf