最近对量化交易非常感兴趣,所以在放假之余研究了一把量化交易。为了方便后续总结,在此开个文章记录。
什么是量化交易?
首先,我们来聊下什么是量化交易。与量化交易相对比的是传统交易方法,如同大型收割机之于锄头镰刀,机枪大炮之于刀剑棍棒。主要用于股市中。如果大家看过基金经理操盘,那大概就应该知道为啥会出现量化交易。传统交易中基金经理往往会在几分钟内买入卖出十几余次,而且基本遵循某些特定的股市变化规律,将这些规律进行量化总结,并自动对资产进行买入卖出就是所谓的“量化交易”。
下面我们来拆解看一把:
1.从一个灵感开始
灵感就是指那些你想验证的可能会盈利的方法,比如银行股可能是良好的投资品种、一旦跨过20日均线后股价会继续涨、流传许久的羊驼交易法等等。灵感获取的方式可以是阅读、听人说、自己悟等等。
这里我们以一个简单的情况为例进行讲解。比如你的灵感是这样的:
如果股价显著低于近几日的平均价,则买入
如果股价显著高于近几日的平均价,则卖出
现在,你想知道这样操作究竟会不会赚钱?
2.把灵感细化成明确的可执行的交易策略
一般灵感都很模糊,需要将其细化成明确的可执行的策略,目的是为了能得到确定的结果,以及为后续程序化准备。比如,你通过阅读了解到索罗斯的反身性概念,想将它应用到股市,这个反身性就很模糊,就需要明确什么条件下买卖,买卖什么品种,买卖多少量等,从而形成一个明确的交易策略,让不同人根据你的描述在相同情形下都能做出相同的操作。
继续以之前那个关于平均价的灵感为例:
如果股价显著低于近几日的平均价,则买入
如果股价显著高于近几日的平均价,则卖出
显然它是不够明确的。比如多低叫显著低于?多高叫显著高于?近几日究竟是几日?买入卖出是买卖多少?我们把它细化:
如果股价低于近20日平均价10%,则用全部可用资金买入
如果股价高于近20日平均价10%,则卖出全部所持的该股票
还有一点不明确的地方,买卖哪个股票呢?我们认为这个交易方法盈利与否应该跟交易哪个股票关系不大,但st股票除外(知道st股票是一类有风险特别大的股票就好,详情请百度),所以股票的选择范围是除st股外的国内A股的所有股票。所以我们进一步细化:
每个交易日监测是除st股外的国内A股的所有股票的股价
如果股价低于近20日平均价10%,则用全部可用资金买入该股票
如果股价高于近20日平均价10%,则卖出全部所持有的该股票
现在我们基本已经把之前的灵感细化成明确的可执行的交易策略。当然,可能还有些地方不够明确,也可能有些细节还不确定要改动,这些可以随时想到随时再改,不必一次做到完美。
3.把策略转成程序
就是把明确后的策略通过编程转成程序,好让计算机能根据历史数据模拟执行该策略,以及能根据实际行情进行反应并模拟交易或真实交易。
简言之,就是把刚刚的策略翻译成计算机可识别的代码语言,即把这个:
每个交易日监测是除st股外的国内A股的所有股票的股价
如果股价低于近20日平均价10%,则用全部可用资金买入该股票
如果股价高于近20日平均价10%,则卖出全部所持有的该股票
写成类似这样的代码(下面的代码并不完全符合,只是展示下大概的样子):
def initialize(context): g.security = ['002043.XSHE','002582.XSHE'] def handle_data(context, data): for i in g.security: last_price = data[i].close average_price = data[i].mavg(20, 'close') cash = context.portfolio.cash if last_price > average_price: order_value(i, cash) elif last_price < average_price: order_target(i, 0)
这样一来,就把刚才细化好策略转成了代码程序,计算机就能运行了。这个过程你可以理解成用计算机能听懂的语言(代码),把你的策略告诉给计算机了。
4.检验策略效果
现在计算机理解了你的策略,你现在可以借助计算机的力量来验证你的策略了。基本的检验策略方法有回测和模拟交易两种方法。
回测是让计算机能根据一段时间的历史数据模拟执行该策略,根据结果评价并改进策略。继续之前的那个均价的策略例子的话就是这样的:
设定初始的虚拟资产比如500000元、一个时期比如20060101到20160101,把这一时期的各种数据如估计股价行情等发给计算机,计算机会利用这些数据模仿真实的市场,执行你刚才告诉它的策略程序。最后计算机会给你一份报告,根据这个报告你就会知道,在20060101的500000元,按照你的策略交易到20160101,会怎样?一般包括盈亏情况,下单情况,持仓变化,以及一些统计指标等,从而你能据此评估交易策略的好坏。
如果结果不好,则需要分析原因并改进。如果结果不错,则可以考虑用模拟交易进一步验证。
模拟交易是让计算机能根据实际行情模拟执行该策略一段时间,根据结果评价并改进策略。与回测不同,回测是用历史数据模拟,模拟交易使用实际的实时行情来模拟执行策略的。举例就是这样:
设定初始的虚拟资产比如500000元,选择开始执行模拟交易的时间点,比如明天。那么从明天开始,股市开始交易,真实的行情数据就会实时地发送到计算机,计算机会利用真实的数据模仿真实的市场,执行你的策略程序。同时,你会得到一份实时更新的报告。这报告类似于回测得到的报告,不同的是会根据实际行情变化更新。同样你能据此评估交易策略的好坏。
可见,回测是用历史数据模拟执行策略,模拟交易是用未来的实际行情模拟执行策略。如果策略在回测与模拟交易的表现都非常好,你可以考虑进行完全真实的真金白银的实盘交易。
5.进行实盘交易并不断维护修正
实盘交易就是让计算机能自动根据实际行情,用真金白银自动执行策略,进行下单交易。注意,这时不再是用虚拟资产模拟交易,亏损和盈利都是真钱。实盘交易一般也会给出一份类似模拟交易的会不断更新的报告,从而不断要观察策略的实盘表现并及时调整与改进策略,使之持续平稳盈利。
如何实现量化交易?
按照我的理解,量化交易实现需要包括如下两个部分:
- 要有各种数据。要有能方便使用的各种投资相关的数据。这要考虑到各种数据的收集、存储、清洗、更新,以及数据取用时的便捷、速度、稳定。
- 还要有一套量化交易的系统,要有能编写策略、执行策略、评测策略的系统。这要考虑到系统对各种策略编写的支持、系统进行回测与模拟的高仿真、系统执行策略的高速、系统评测策略的科学可靠全方面。
这里本人用 zvt 搭建了一套量化交易框架
链接在这里:https://github.com/zvtvz/zvt
所以以把玩的这个量化交易框架为例看看如果我们希望做量化交易应该准备哪些东西:
1.首先是数据:
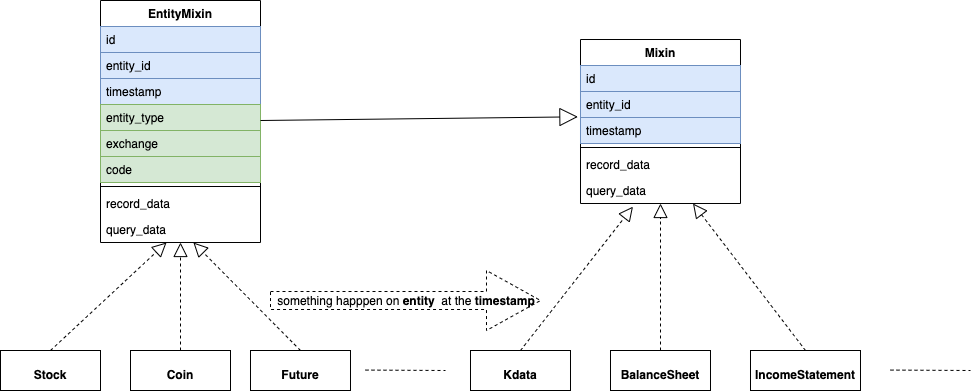
“数据”就是投资标的 在某时间点(段) 所发生的事情的描述。其中,投资标的,叫entity;时间点(段),叫timestamp;事情的描述根据事情的不同而具有不同的属性。
历史数据可以通过对zvt给的链接导入:
东财数据: https://pan.baidu.com/s/1CMAlCRYwlhGVxS6drYUEgA 提取码: q2qn
资金流,板块数据(新浪): https://pan.baidu.com/s/1eusW65sdK_WE4icnt8JS1g 提取码: uux3
市场概况,沪/深港通,融资融券数据(聚宽): https://pan.baidu.com/s/1ijrgjUd1WkRMONrwRQU-4w 提取码: dipd
In [1]: from zvt.domain import * In [2]: global_schemas [zvt.domain.dividend_financing.DividendFinancing, zvt.domain.dividend_financing.DividendDetail, zvt.domain.dividend_financing.SpoDetail...]
实时数据需要通过脚本抓取
# -*- coding: utf-8 -*-
import logging
import time
from apscheduler.schedulers.background import BackgroundScheduler
from zvt import init_log
from zvt.domain import *
logger = logging.getLogger(__name__)
sched = BackgroundScheduler()
# 自行更改定时运行时间
@sched.scheduled_job('cron', hour=2, minute=00)
def run():
while True:
try:
FinanceFactor.record_data()
BalanceSheet.record_data()
IncomeStatement.record_data()
CashFlowStatement.record_data()
break
except Exception as e:
logger.exception('finance recorder error:{}'.format(e))
time.sleep(60)
if __name__ == '__main__':
init_log('eastmoney_finance_recorder.log')
run()
sched.start()
sched._thread.join()
run zvt :
2.编写策略:
zvt 里面的factor分为三类: FilterFactor, ScoreFacor, StateFactor.
TechnicalFactor
该factor为计算各种技术指标的算法模板类,基于它可以构造出用于选股和交易的Factor
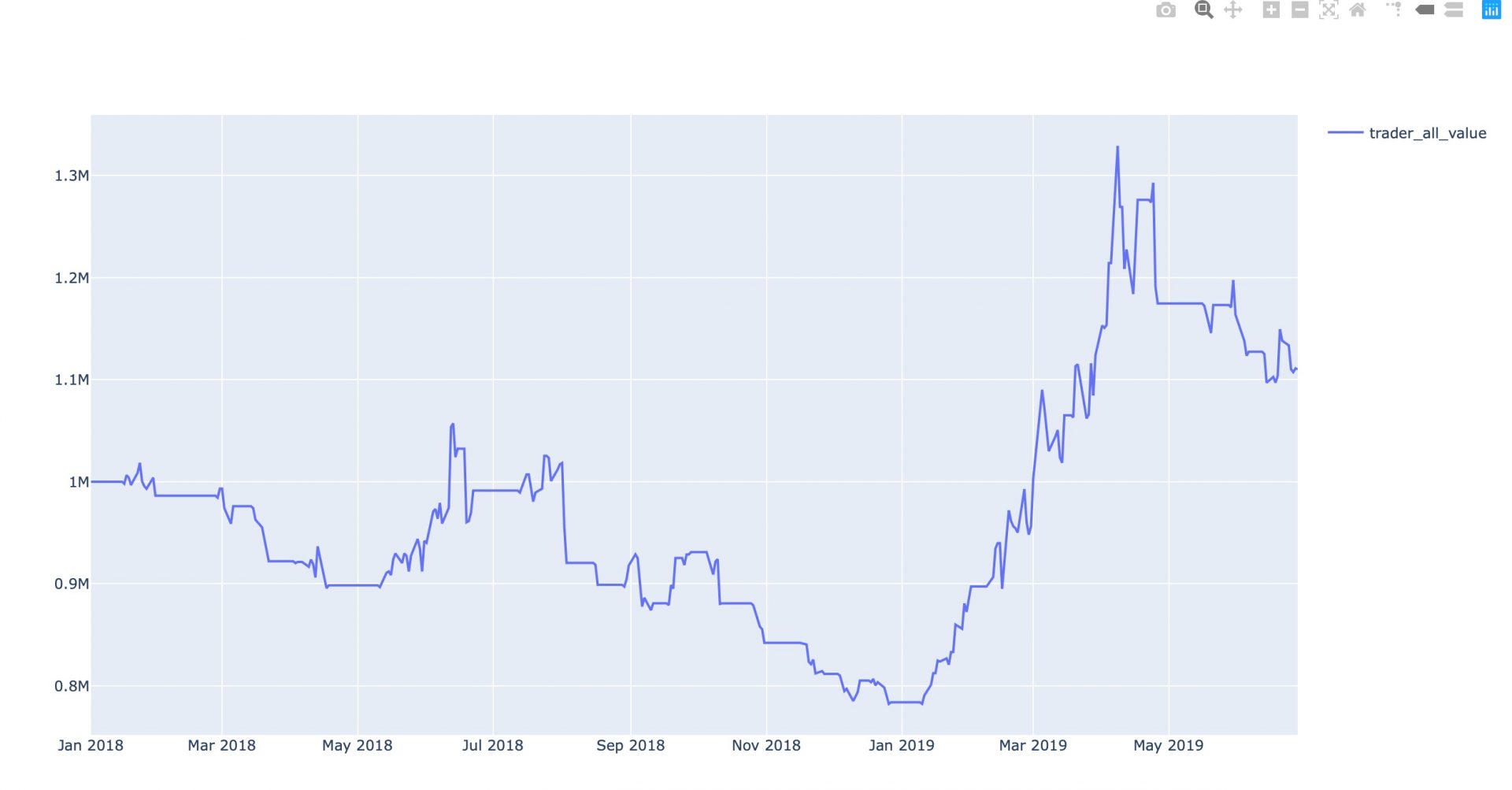
factor = TechnicalFactor(codes=['000338'], start_timestamp='2018-01-01', end_timestamp='2019-02-01',
indicators=['ma', 'ma'],
indicators_param=[{'window': 5}, {'window': 10}])
factor.draw_with_indicators()
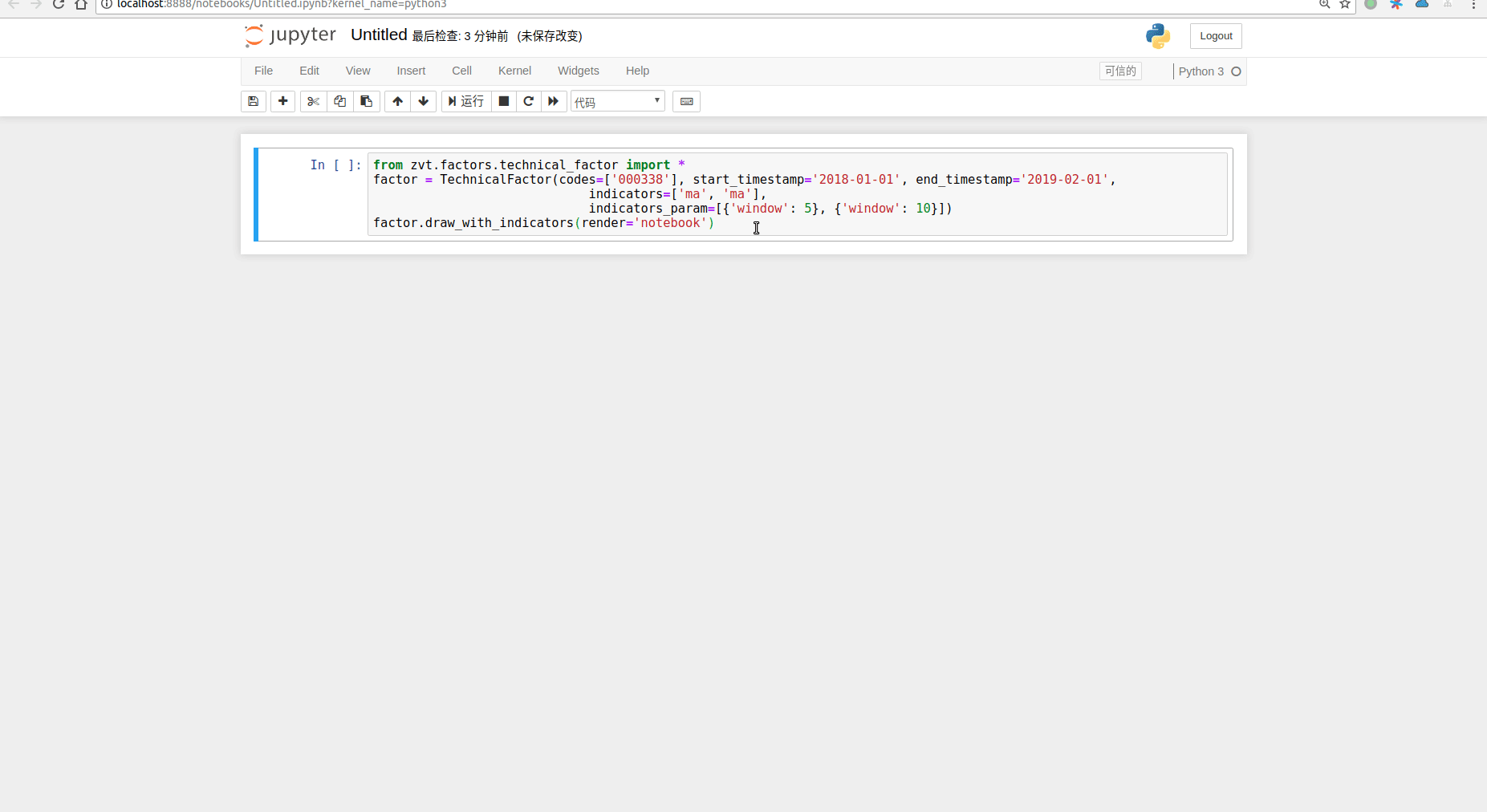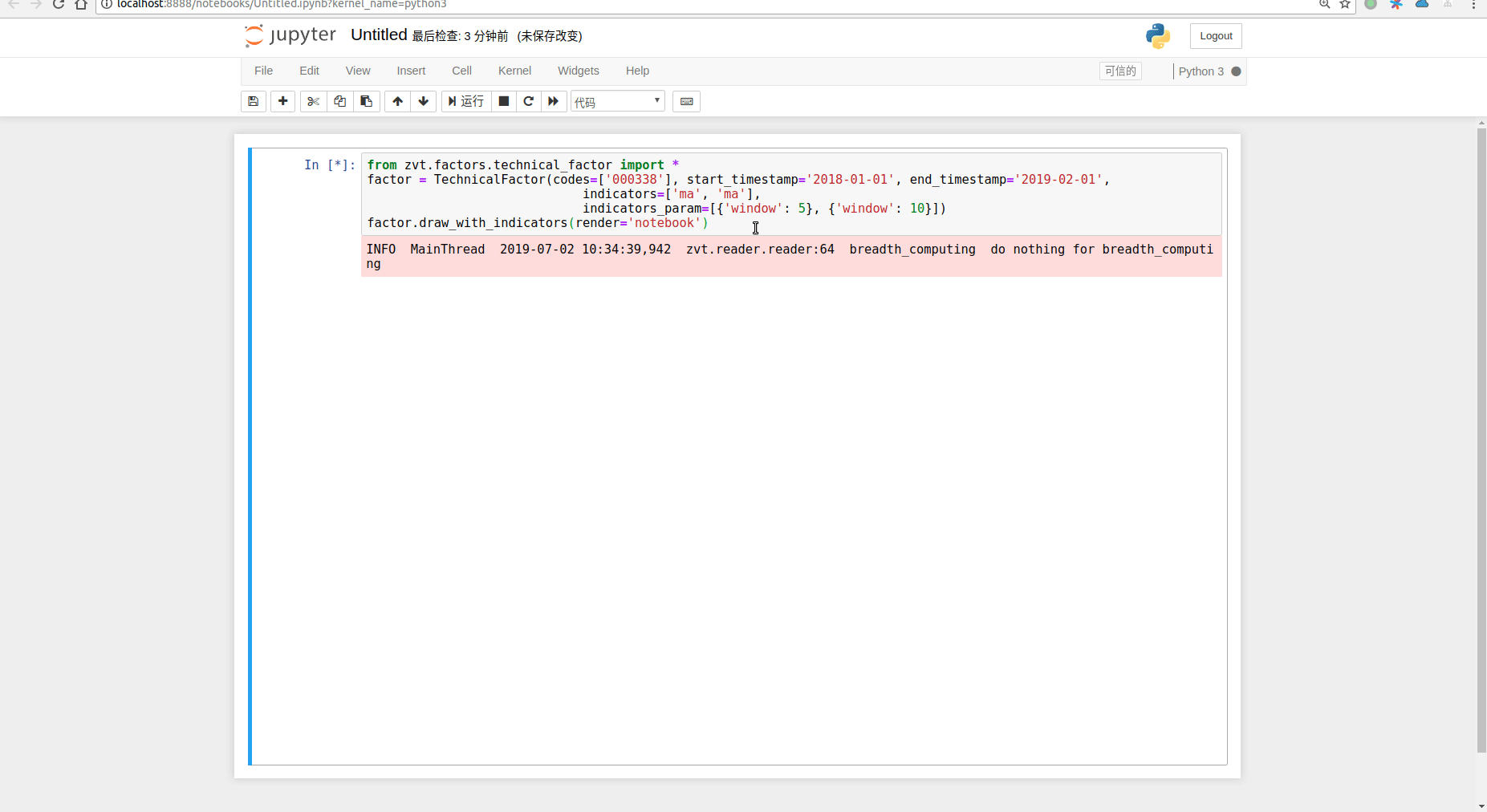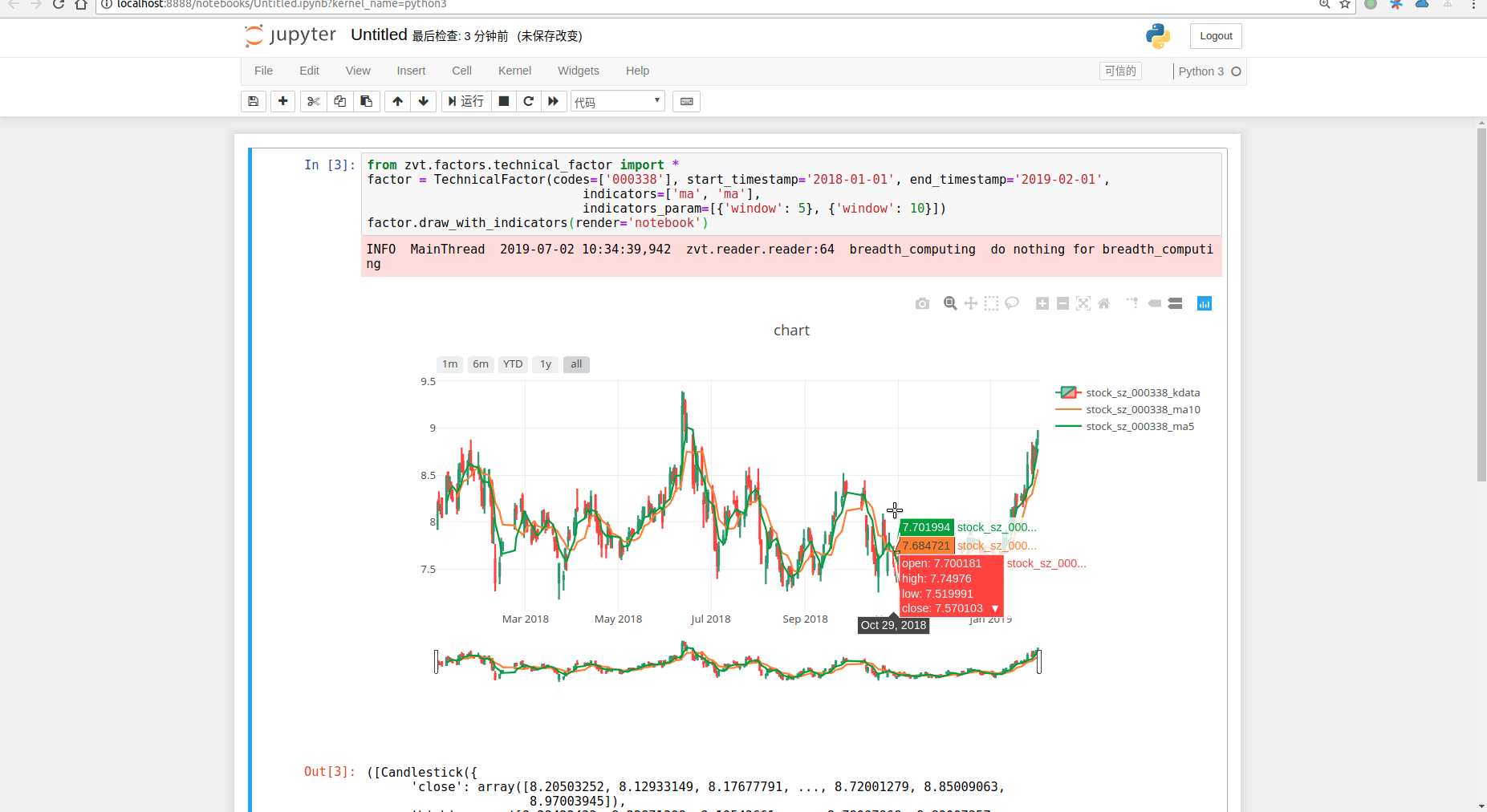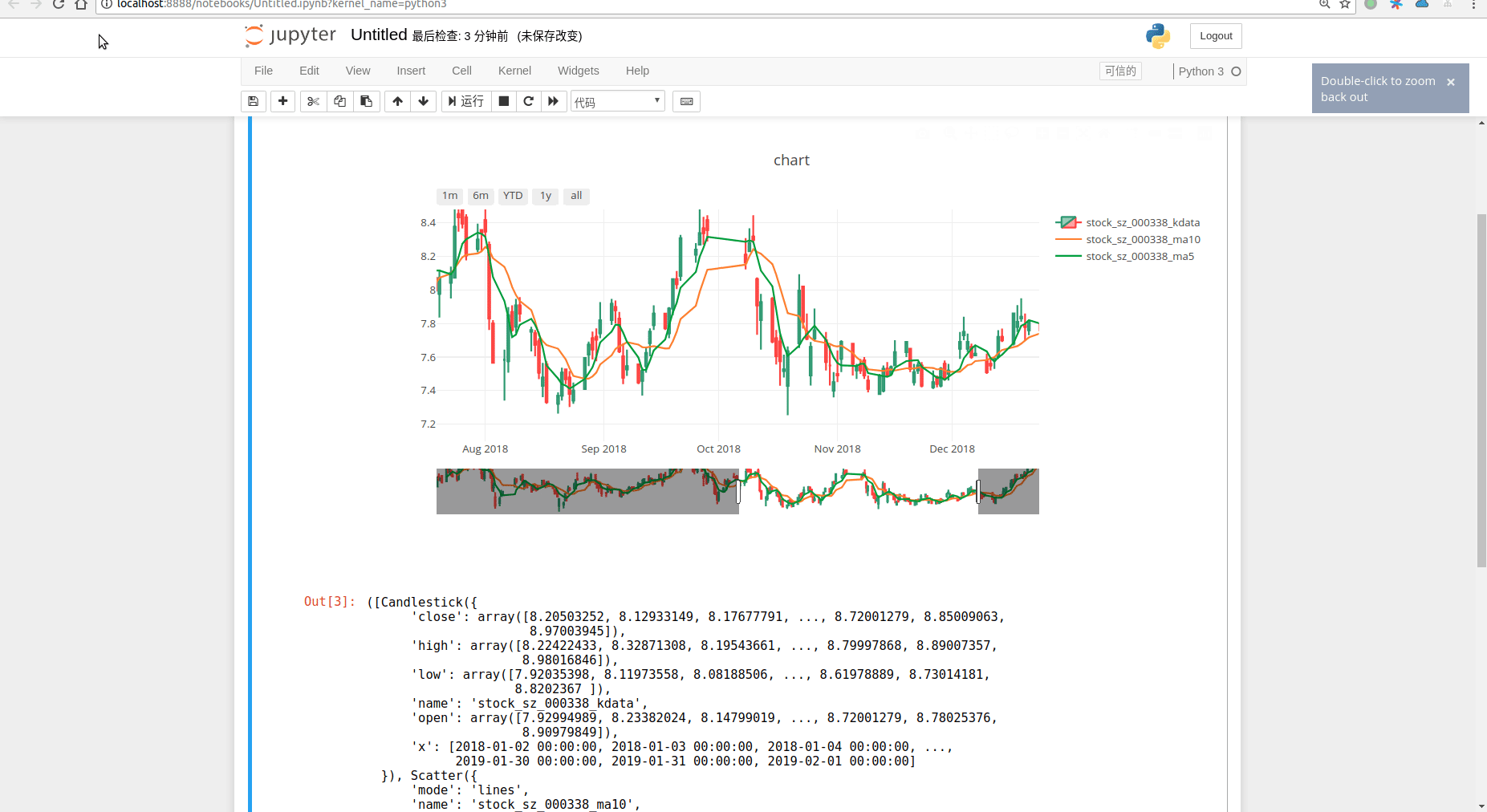
技术买卖指标
基于TechnicalFactor你可以构造自己的FilterFactor,比如,均线交叉买卖:
class CrossMaFactor(TechnicalFactor):
def __init__(self,
entity_ids: List[str] = None,
entity_type: Union[str, SecurityType] = SecurityType.stock,
exchanges: List[str] = ['sh', 'sz'],
codes: List[str] = None,
the_timestamp: Union[str, pd.Timestamp] = None,
start_timestamp: Union[str, pd.Timestamp] = None,
end_timestamp: Union[str, pd.Timestamp] = None,
columns: List = None, filters: List = None,
provider: Union[str, Provider] = 'netease',
level: IntervalLevel = IntervalLevel.LEVEL_1DAY,
category_field: str = 'security_id',
# child added arguments
short_window=5,
long_window=10) -> None:
self.short_window = short_window
self.long_window = long_window
super().__init__(entity_ids, entity_type, exchanges, codes, the_timestamp, start_timestamp, end_timestamp,
columns, filters, provider, level, category_field,
indicators=['ma', 'ma'],
indicators_param=[{'window': short_window}, {'window': long_window}], valid_window=long_window)
def compute(self):
super().compute()
s = self.pipe_df['ma{}'.format(self.short_window)] > self.pipe_df['ma{}'.format(self.long_window)]
self.result_df = s.to_frame(name='score')
def on_category_data_added(self, category, added_data: pd.DataFrame):
super().on_category_data_added(category, added_data)
# TODO:improve it to just computing the added data
self.compute()
ScoreFactor
ScoreFactor内置了分位数算法(quantile),你可以非常方便的对其进行扩展.
下面展示一个例子:对个股的营收,利润增速,资金,净资产收益率进行评分
class FinanceGrowthFactor(ScoreFactor):
def __init__(self,
entity_ids: List[str] = None,
entity_type: Union[str, SecurityType] = SecurityType.stock,
exchanges: List[str] = ['sh', 'sz'],
codes: List[str] = None,
the_timestamp: Union[str, pd.Timestamp] = None,
start_timestamp: Union[str, pd.Timestamp] = None,
end_timestamp: Union[str, pd.Timestamp] = None,
columns: List = [FinanceFactor.op_income_growth_yoy, FinanceFactor.net_profit_growth_yoy,
FinanceFactor.rota,
FinanceFactor.roe],
filters: List = None,
provider: Union[str, Provider] = 'eastmoney',
level: IntervalLevel = IntervalLevel.LEVEL_1DAY,
category_field: str = 'security_id',
keep_all_timestamp: bool = True,
fill_method: str = 'ffill',
effective_number: int = None,
depth_computing_method='ma',
depth_computing_param={'window': '365D', 'on': 'timestamp'},
breadth_computing_method='quantile',
breadth_computing_param={'score_levels': [0.1, 0.3, 0.5, 0.7, 0.9]}) -> None:
super().__init__(FinanceFactor, entity_ids, entity_type, exchanges, codes, the_timestamp, start_timestamp,
end_timestamp, columns, filters, provider, level, category_field,
keep_all_timestamp, fill_method, effective_number, depth_computing_method,
depth_computing_param, breadth_computing_method, breadth_computing_param)
总结:
量化交易市场有较为成熟开源工具,但仍属于新领域的。通常一个投资者做量化交易所需要做的准备,就如同让一个农民自己去造一个大型收割机,而且还是从挖矿开始做起,极度困难,所以量化交易最初在金融与科技最为发达的美国由少数顶级精英发起的。
做个备忘 End。