如果你打开 Storm 官网,你会在原理介绍发现这句话:
MapReduce, Hadoop, and related technologies have made it possible to store and process data at scales previously unthinkable. Unfortunately, these data processing technologies are not realtime systems, nor are they meant to be. There’s no hack that will turn Hadoop into a realtime system; realtime data processing has a fundamentally different set of requirements than batch processing. Storm fills that hole.(MapReduce,Hadoop 和其大数据的相关技术可以使之前无法想象的大规模数据存储和数据处理成为可能。但是这些数据处理技术都不是实时计算,实时数据处理与批处理有着截然不同的要求。Storm 填补了这里的空白。)
其实除了 Storm 还有类似 Flink 这样的实时处理框架,那么这两者的区别究竟在哪儿呢?正好最近疫情在家隔离,也得空出来仔细研究下 Realtime Analytics 场景下两个比较有特点的实时数据处理框架。
Apache Storm是一个开源,可容错,可扩展的实时流处理计算系统。它是实时分布式数据处理的框架。它着重于事件处理或流处理。Storm实现了一种容错机制来执行计算或调度事件的多个计算。
Storm 核心架构
架构图如下所示:

Storm 核心概念及工作流程
简单概括下工作流程大概是:
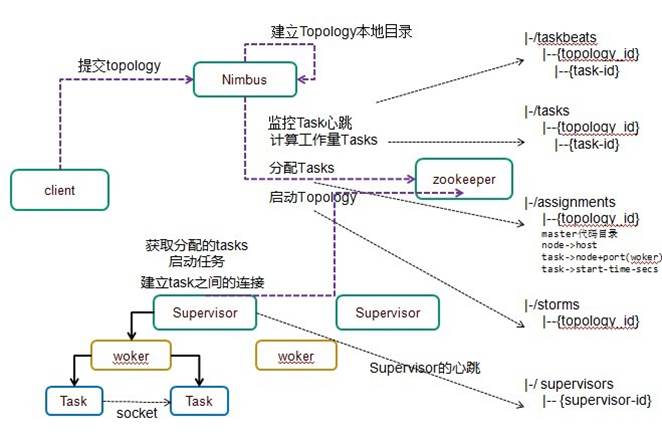
1、客户端编写Storm应用程序,编译打包成Storm可识别的Topology图,上传到Nimbus主节点
2、Nimbus将Topology解析,把任务分发到各个Supervisor节点
3、Supervisor接收到任务后启动Executor,运行Task任务
Nimbus:主节点运行的守护进程,很类似于 Hadoop 的“JobTracker”。Nimbus 负责在集群内进行代码分发,主要工作是将任务分配给机器,并监控故障。
Supervisor:工作节点运行的守护进程,主要能力是监听分配给其机器的工作,并根据 Nimbus 分配给它的内容在必要时启动和停止工作进程。每个工作进程执行一个子集;正在运行的工作进程由分布在多个机器上的多个工作进程组成。
当然 Nimbus 和 Supervisor 之间的所有协调都是通过 Zookeeper 集群完成的。
Streams (流)
除了这些之外,Storm 还有另外一个核心概念是 Streams (流),大概的工作性质我在官网找了下,是这样的
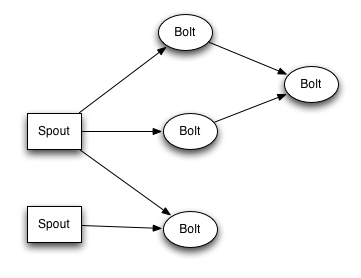
流的一些情况如下:
Spout:Spout 是流的 Source(源端) ,它主要负责的是流的来源接入,E.g. 可以使用 Spout 来接收消息队列或者 API 信息来进行下一步计算。
Bolt:Bolt 是流的 Consumes(消费端),它主要负责具体流式计算部分,如需要多个步骤也可以级联运行。Bolt 可以做任何事情,比如运行函数、过滤元组、流聚合、流连接、与数据库对接等等。
Topology (拓扑)
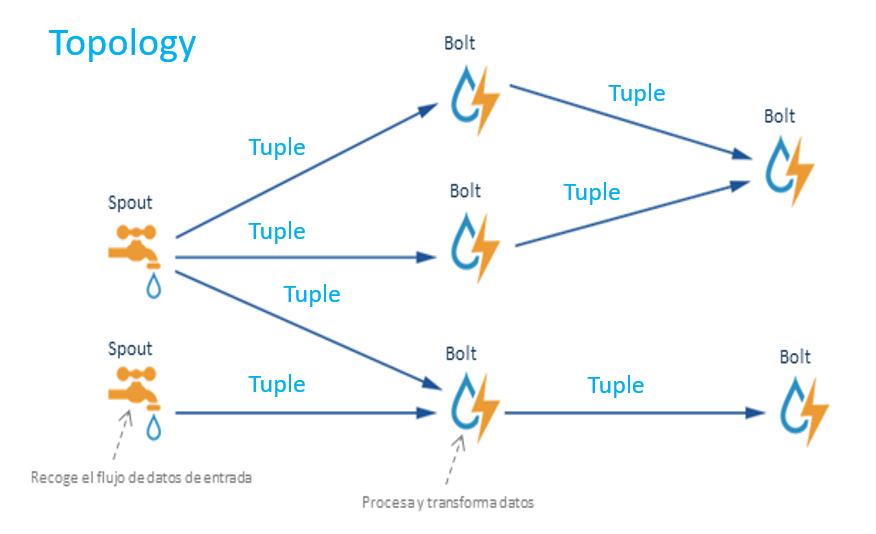
Tuple:数据流,Topology 中传递的数据。
Spout及Bolt,Tuple 统一称为一个 Topology,每个 Topology 都将永远运行,直到手动杀死它。同时 Storm 会自动重新分配任何失败的任务,Storm 将保证不会丢失数据,即使机器宕机和消息丢失。
一个简单的 Topology 代码:
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("words", new TestWordSpout(), 10);
builder.setBolt("exclaim1", new ExclamationBolt(), 3)
.shuffleGrouping("words");
builder.setBolt("exclaim2", new ExclamationBolt(), 2)
.shuffleGrouping("exclaim1");
Topplogy 的运行流程我在网上找了一个图,说的还算是比较清楚,大概是这样的;
ACK 机制
Ack 是 Storm 中的消息容错机制,Ack 的使用和算法是 storm 最突出的亮点。
由 Spout 流出的每一个 tuple,直到最后 bolt 处理结束,都会被 ack 标记为成功或失败,失败数据可重新返回Spout进行处理,保障数据的可靠性,这就是 Storm 中 ack 机制。
storm 会专门启动若干 acker 线程,来追踪 tuple 的处理过程。可以使用 Config.TOPOLOGY_ACKERS 为拓扑配置中的拓扑设置acker任务的数量。Storm 默认 TOPOLOGY_ACKERS 为每个 worker 一个任务。
每一个 Tuple 在 Spout 中生成的时候,都会分配到一个64位的 messageId。通过对 messageId 进行哈希我们可以执行要对哪个 acker 线程发送消息来通知它监听这个 Tuple。
acker线程收到消息后,会将发出消息的 Spout 和那个 messageId 绑定起来。然后开始跟踪该 tuple 的处理流程。如果这个 tuple 全部都处理完,那么 acker 线程就会调用发起这个tuple 的那个 spout 实例的 ack()方法。如果超过一定时间这个 tuple 还没处理完,那么 acker 线程就会调用对应 spout 的 fail()方 法,通知 spout 消息处理失败。spout 组件就可以重新发送这个 tuple。
每个元组都知道它存在于它们的元组树中的所有 spout 元组的 id。当在 Bolt 中发起创建一个新元组时,来自元组锚点的 spout 元组 ID 将被复制到新元组中。当元组被确认时,它会向 acker 进程任务发送一条有关元组树被更改的信息,告诉 acker “在树中完成了创建了 spout 元组,这个 spout 元组归属于我”。
例如,如果元组“D”和“E”是基于元组“C”创建的,下面是当“C”被确认时元组树的变化:
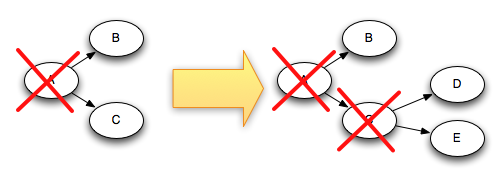
由于在添加“D”和“E”的同时从树中删除“C”,因此树永远不会完成。
Ack 机制中:
1、在规定时间内,如果 spout 收到 ack 响应,则认为改tuple被成功处理
2、在规定时间内,spout 没有收到 ack 响应或收到 fail 响应,则认为该tuple处理失败
3、超过规定时间默认标记为失败,通过 Config.TOPOLOGY_MESSAGE_TIMEOUT_SECS 设置超时时间,这里默认是30秒。
Ack 整体的异常重试策略是这样:
由于任务终止,元组没有被确认:在这种情况下,失败元组的树最开始的 spout 元组 ID 将超时并被重播。
Acker 任务失败:在这种情况下,acker 跟踪的所有 spout 元组都将超时并被重播。
Spout 任务失败:在这种情况下,spout 源负责重放消息。例如,当客户端断开连接时,像 Kestrel 和 RabbitMQ 这样的队列会将所有待处理的消息放回队列中。
ack 机制除了数据容错之外,还可以用作限流:
当 bolt 处理速度跟不上 spout 生产速度时,可以通过设置 pending 数量来进行限流,当 spout 有等于或超过 pending 数的 tuple 没有收到 ack 或 fail 响应时,跳过执行 nextTuple, 从而限制 spout 发送数据。
Config.TOPOLOGY_MAX_SPOUT_PENDING 可设置 pending 数量。
同样,如果需要数据可重放,可以通过将 acker bolt 的数量 Config.TOPOLOGY_ACKERS 设置为 0 来禁用容错。
由此可以看出,Storm 的可靠性机制是完全分布式的、可扩展的和容错的。这个也是 Storm 的核心亮点之一。
Storm 并行工作
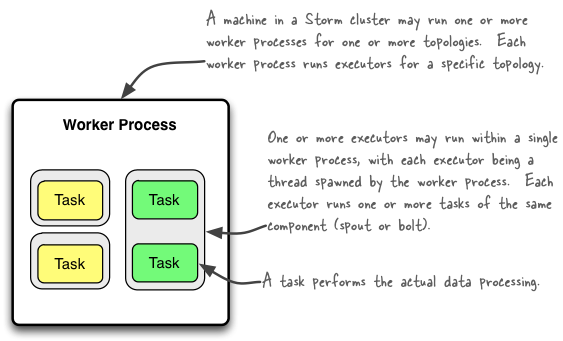
概念如下:
一个 Worker 执行 Topplogy 的一个子集。一个工作进程属于一个特定的 Topplogy 结构,并且可以为这个 Topplogy 结构的一个或多个组件(spouts 或 bolts)运行一个或多个执行器。一个正在运行的 Topplogy 由在 Storm 集群中的多台机器上运行的许多此类进程组成。
一个 Executor 是由一个工作进程催生了一个线程。它可以为同一个组件(spout 或 bolt)运行一项或多项任务。
一个 Task 实际的数据处理——在代码中实现的每个 spout 或 bolt 都在集群中执行尽可能多的任务。在拓扑的整个生命周期中,组件的任务数量始终相同,但组件的执行器(线程)数量可能会随时间变化。E.g. #threads ≤ #tasks. 默认情况下,Task 数设置为与Executor 数相同,即 Storm 为每个线程运行一个任务。
由此可见,在Storm中,Worker不是组件执行的最小单位。Executor才是,Executor可以理解为是一个线程。我们在创建topology的时候,可以设置执行spout的线程数和bolt的线程数。
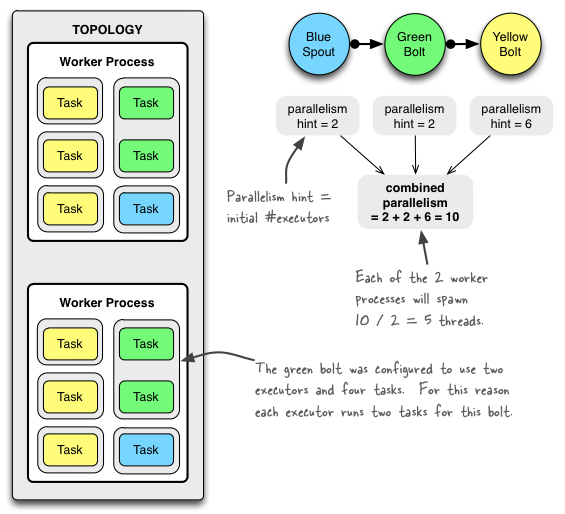
假设bluespout,greenbolt和yellowbolt的线程数加起来设置了10个,然后设置了2个worker,那么这10个线程可能就会被分配到2个worker中,代码及分配结果如下:
Config conf = new Config();
conf.setNumWorkers(2); // use two worker processes
topologyBuilder.setSpout("blue-spout", new BlueSpout(), 2); // set parallelism hint to 2
topologyBuilder.setBolt("green-bolt", new GreenBolt(), 2)
.setNumTasks(4)
.shuffleGrouping("blue-spout");
topologyBuilder.setBolt("yellow-bolt", new YellowBolt(), 6)
.shuffleGrouping("green-bolt");
StormSubmitter.submitTopology(
"mytopology",
conf,
topologyBuilder.createTopology()
);
总结
如果你想要的是一个允许增量计算的,无状态的高速事件处理系统,Storm会是最佳选择。它完善的 ACK 容错机制可最大限度的保证每个并发Worker执行。但 Storm 的安装和部署有些棘手。它仍然依赖 Zookeeper 集群来与状态,集群和 Task 信息进行协调。