不知不觉,从8月份敲下第一行需求描述到现在,已经三个月过去了。这三个月对我来讲很痛苦,对研发和合作团队来讲也很痛苦。这是一项浩大的工程,从后台到控制流再到前端,跨团队合作,几个新瓜蛋子愣是把整个触发器合作流程趟了个遍。真的很不容易。也成功完成了最重要的触发器对接。
好在,大差不差的产品成功上线了,这对整个后续的产品协同和产品接入规划其实有着很深刻的意义。对产品如是,对研发也如是。
其实这些都是题外话了,这次我想分享一些关于触发器产品的思考和总结。也顺带给其他做B端的一些同学警醒和建议。
首先在做一个功能前,需要解决的问题是这个东西有没有用户用。其次才是怎么让用户用的爽。这其实是一个需求的原动力,推合作方如此,推客户更是如此。所以在做需求前,为了不犯错,其实我在私下也会做很多分析&调研。能做是一方面,做出来有价值其实又是另一方面。
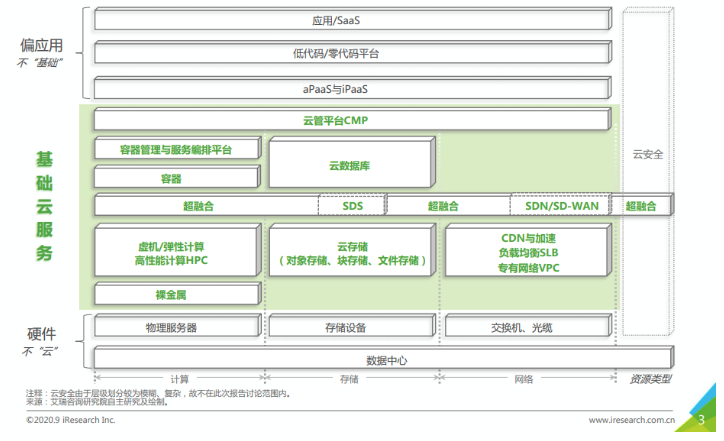
上图是艾瑞咨询发的基础云服务行业发展概览图。其实本身云函数其实就是基础云设施,只是它的粒度足够小,足够便捷,也足够即用即走。它可能短时间无法替代主流的虚拟机,数据库,存储,但是它有一个最大的优势 ———— 无孔不入。做触发器其实就是渗入到各个云产品,让各个云产品所产生的事件都能被函数消费,处理。
更准确一点,就是把上图的核心基础服务全部接入函数计算。这带来的价值是不可估量的,这里就以我们已经接入并发布的CLS触发器场景来讲吧,链接在这里。这个其实只是前期调研的冰山一角,我们还探索了很多类似这样的细分场景。它小吗?小,小到根本不值一提,但是它确实解决了用户在日志场景下处理数据的诉求。而且在这些场景下,云函数是不可替代的,其他云服务都干不了这事儿。当然除非另外产品化能力,但与之而来的是高昂的成本。
以这个例子阐述,就可以明白触发器对整个FaaS生态的重要了吧,简单点就是接一个触发器可能会有10个左右的细分场景,接十个就是100个细分场景,在配合函数间调用,或者工作流伴随着用户理解函数计算的概念提升,这里会越来越具价值和战略意义。
那么问题来了,这么多云产品,从哪块入手呢?这个问题其实很简单,使用排除法+简单分析就完全能搞定:
- 函数本身提供的就是基础计算能力,所以 VM虚拟机,容器 等一系列计算产品本身就搭不上边
- 以艾瑞咨询发布的概览图为例子,我们能搞的只有 对象存储/CDN/LB/数据库?对象存储其实很早就已经有了,CDN 其实主要场景还是刷新,LB也算但对函数来讲不太刚需,数据库本身就有事务的概念所以这里对函数来讲入局的希望不大。
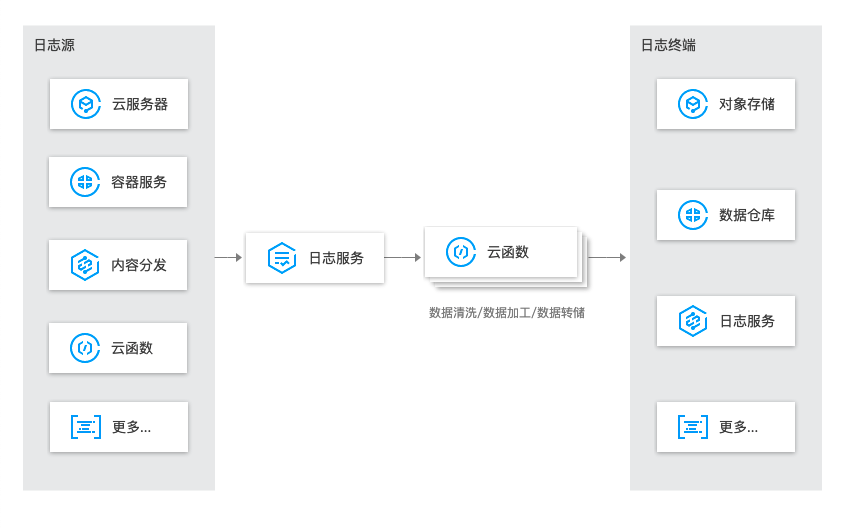
那我们换个思维,除了这些开发者最关注的是啥?那首当其冲的就是日志!日志永远是所有业务最核心而且开发者最常用的。简单梳理了下,便画出了这样的业务流,通过 CLS+SCF 构建整个云上业务的数据流处理枢纽,一个负责数据采集,一个负责数据计算,简直不要太搭:
大方向有了,客户场景也有了,那接下来就是细节设计了。我们想到 AWS Lambda 一定会惊叹于它海量的数据源支持,它其实是Faas乃至整个云服务的祖师爷。过庙留香,何况带我入行的师傅说过一句让我至今记忆犹新的话“如果能把产品策略抄到AWS 90%,其实就能干掉 99% 的做云服务的产品经理”。所以这尊佛还是要拜拜的。
触发器的核心其实就是 event,没有什么能比定一个靠谱的 event 对触发器更重要了,这里调研了三个方案:
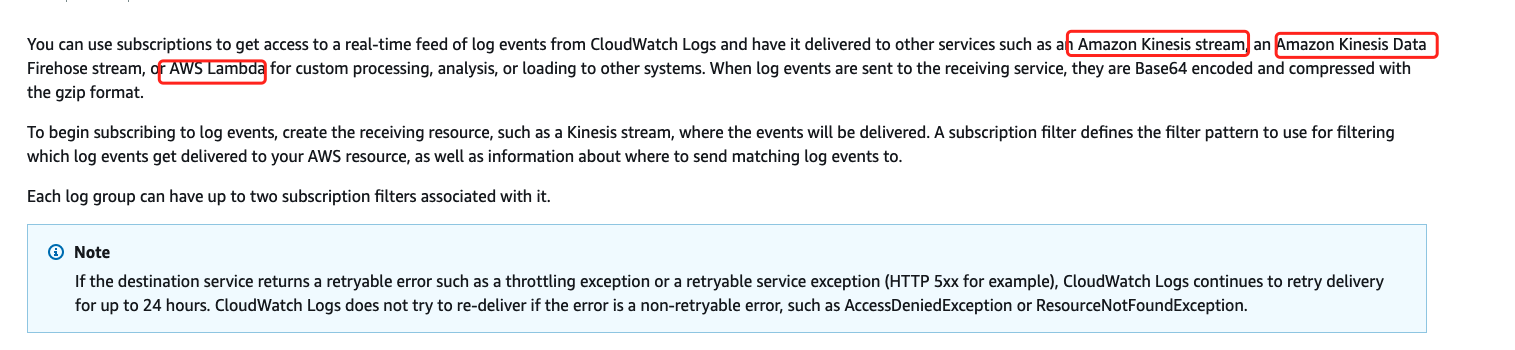
祖师爷 AWS:
AWS的做法十分精巧,直接通过gzip压缩+base64来把日志流的日志投递到函数 event,按照条数依次投递到用户函数,具体做法如下:
这个是函数收到的event:
{
"awslogs": {
"data": "ewogICAgIm1lc3NhZ2VUeXBlIjogIkRBVEFfTUVTU0FHRSIsCiAgICAib3duZXIiOiAiMTIzNDU2Nzg5MDEyIiwKICAgICJsb2dHcm91cCI6I..."
}
}
这个是解压+解码后的数据结构:
{
"messageType": "DATA_MESSAGE",
"owner": "123456789012",
"logGroup": "/aws/lambda/echo-nodejs",
"logStream": "2019/03/13/[$LATEST]94fa867e5374431291a7fc14e2f56ae7",
"subscriptionFilters": [
"LambdaStream_cloudwatchlogs-node"
],
"logEvents": [
{
"id": "34622316099697884706540976068822859012661220141643892546",
"timestamp": 1552518348220,
"message": "REPORT RequestId: 6234bffe-149a-b642-81ff-2e8e376d8aff\tDuration: 46.84 ms\tBilled Duration: 100 ms \tMemory Size: 192 MB\tMax Memory Used: 72 MB\t\n"
}
]
}
这样做大大提升了传输效率并有效降低了用户使用成本。但是,AWS 这里只支持了日志流的日志,意味着EC2其实不能采集到Lambda的,这点完全不可取。
国内老大 阿里云:
阿里云其实做法很讨巧,知道日志服务都为数据量极大的场景,所以他们只传了数据游标,大概是这样的:
{
"parameter": {},
"source": {
"endpoint": "http://cn-shanghai-intranet.log.aliyuncs.com",
"projectName": "log-com",
"logstoreName": "log-en",
"shardId": 0,
"beginCursor": "MTUyOTQ4MDIwOTY1NTk3ODQ2Mw==",
"endCursor": "MTUyOTQ4MDIwOTY1NTk3ODQ2NA=="
},
"jobName": "1f7043ced683de1a4e3d8d70b5a412843d817a39",
"taskId": "c2691505-38da-4d1b-998a-f1d4bb8c9994",
"cursorTime": 1529486425
}
这个做法其实是牺牲了用户体验,并且变相延长了函数的运行事件,如果游标设置过大会导致函数一直超时。这个方案其实很LOW,最起码不符合触发器的定义。按照阿里的做法用户需要使用特定的SDK来获取游标信息,代码如下:
# -*- coding: utf-8 -*-
import logging
import json
from aliyun.log import LogClient
from time import time
def logClient(endpoint, creds):
logger = logging.getLogger()
logger.info('creds info')
logger.info(creds.access_key_id)
logger.info(creds.access_key_secret)
logger.info(creds.security_token)
accessKeyId = 'your accessKeyId'
accessKey = 'your accessKeyId scr'
client = LogClient(endpoint, accessKeyId, accessKey)
return client
def handler(event, context):
logger = logging.getLogger()
logger.info('start deal SLS data')
logger.info(event.decode().encode())
info_arr = json.loads(event.decode())
fetchdata(info_arr['source'],context)
return 'hello world'
年轻人,讨巧可以,但是这么搞用户不会投诉吗?把自己的触发器成本完全转嫁到用户头上。
华为云:
讲真,我真的不想说。抄都不认真抄,当真是垃圾云啊。
{
"lts": {
"data": "ewogICAgICAgICJsb2dzIjpbewogICAgICAgICAgICAgICAgIm1lc3NhZ2UiOiIyMDE4LTA2LTI2LzE4OjQwOjUzIFtJTkZdIFtjb25maWcuZ286NzJdIFN1Y2Nlc3NmdWxseSBsb2FkZWQgZ2VuZXJhbCBjb25maWd1cmF0aW9uIGZpbGVcXHJcXG4iLAogICAgICAgICAgICAgICAgInRpbWUiOjE1MzAwMDk2NTMwNTksCiAgICAgICAgICAgICAgICAiaG9zdF9uYW1lIjoiZWNzLXRlc3RhZ2VudC5ub3ZhbG9jYWwiLAogICAgICAgICAgICAgICAgImlwIjoiMTkyLjE2OC4xLjk4IiwKICAgICAgICAgICAgICAgICJwYXRoIjoidXNyL2xvY2FsL3RlbGVzY29wZS9sb2cvY29tbW9uLmxvZyIsCiAgICAgICAgICAgICAgICAibG9nX3VpZCI6IjY2M2Q2OTMwLTc5MmQtMTFlOC04YjA4LTI4NmVkNDg4Y2U3MCIsCiAgICAgICAgICAgICAgICAibGluZV9ubyI6NjE1CiAgICAgICAgICAgIH0sCiAgICAgICAgICAgIHsKICAgICAgICAgICAgICAgICJtZXNzYWdlIjoiMjAxOC0wNi0yNi8xODo0MDo1MyBbV1JOXSBbY29uZmlnLmdvOjgyXSBUaGUgcHJvamVjdElkIG9yIGluc3RhbmNlSWQgb2YgY29uZmlnLmpzb24gaXMgbm90IGNvbnNpc3RlbnQgd2l0aCBtZXRhZGF0YSwgdXNlIG1ldGFkYXRhLlxcbiIsCiAgICAgICAgICAgICAgICAidGltZSI6MTUzMDAwOTY1MzA1OSwKICAgICAgICAgICAgICAgICJob3N0X25hbWUiOiJlY3MtdGVzdGFnZW50Lm5vdmFsb2NhbCIsCiAgICAgICAgICAgICAgICAiaXAiOiIxOTIuMTY4LjEuOTgiLAogICAgICAgICAgICAgICAgInBhdGgiOiIvdXNyL2xvY2FsL3RlbGVzY29wZS9sb2cvY29tbW9uLmxvZyIsCiAgICAgICAgICAgICAgICAibG9nX3VpZCI6IjY2M2Q2OTMwLTc5MmQtMTFlOC04YjA5LTI4NmVkNDg4Y2U3MCIsCiAgICAgICAgICAgICAgICAibGluZV9ubyI6NjE2CiAgICAgICAgICAgIH0sCiAgICAgICAgICAgIHsKICAgICAgICAgICAgICAgICJtZXNzYWdlIjoiIEluIGNvbmYuanNvbiwgcHJvamVjdElkIGlzIFtdLCBpbnN0YW5jZUlkIGlzIFtdLiBNZXRhRGF0YSBpcyB7NDU0MzI5M2EtNWIyYy00NGM0LWI3YTAtZGUyMThmN2YyZmE2IDYyODBlMTcwYmQ5MzRmNjBhNGQ4NTFjZjVjYTA1MTI5ICB9XFxyXFxuIiwKICAgICAgICAgICAgICAgICJ0aW1lIjoxNTMwMDA5NjUzMDU5LAogICAgICAgICAgICAgICAgImhvc3RfbmFtZSI6ImVjcy10ZXN0YWdlbnQubm92YWxvY2FsIiwKICAgICAgICAgICAgICAgICJpcCI6IjE5Mi4xNjguMS45OCIsCiAgICAgICAgICAgICAgICAicGF0aCI6Ii91c3IvbG9jYWwvdGVsZXNjb3BlL2xvZy9jb21tb24ubG9nIiwKICAgICAgICAgICAgICAgICJsb2dfdWlkIjoiNjYzZDY5MzAtNzkyZC0xMWU4LThiMGEtMjg2ZWQ0ODhjZTcwIiwKICAgICAgICAgICAgICAgICJsaW5lX25vIjo2MTcKICAgICAgICAgICAgfQogICAgICAgICAgICBdLAogICAgICAgICJvd25lciI6ICI2MjgwZTE3MGJkOTM0ZjYwYTRkODUxY2Y1Y2EwNTEyOSIsCiAgICAgICAgImxvZ19ncm91cF9pZCI6ICI5N2E5ZDI4NC00NDQ4LTExZTgtOGZhNC0yODZlZDQ4OGNlNzAiLAogICAgICAgICJsb2dfdG9waWNfaWQiOiAiMWE5Njc1YTctNzg0ZC0xMWU4LTlmNzAtMjg2ZWQ0ODhjZTcwIgogICAgICAgIH0="
}
}
华为云直接把格式做了一层Base64就投递给函数了!!!!
why? 产品经理该被炒了把,这层Base64有啥意义? AWS做Base64是因为人家做了gzip解压啊,用句老话真的是脱裤子放屁多此一举。不仅增加了用户成本,而且对整个触发器没有任何收益,就是单单抄了个AWS皮毛,怕不是在逗我。这种产品搞出来是开玩笑的吧。
我不相邪,专门查了他们的demo,如下:
import json
import base64
import sys
import os
import requests
from com.obs.client.obs_client import ObsClient
from com.obs.models.put_object_header import PutObjectHeader
from com.obs.models.get_object_header import GetObjectHeader
from com.obs.models.get_object_request import GetObjectRequest
from com.obs.models.server_side_encryption import SseKmsHeader, SseCHeader
from com.obs.log.Log import *
current_file_path = os.path.dirname(os.path.realpath(__file__))
# append current path to search paths, so that we can import some third party libraries.
sys.path.append(current_file_path)
.......
path_style = Truedef handler(event, context):
# Obtains the data of lts logs.
print ("*********the data of lts logs********")
encodingData = event["lts"]["data"]
data = base64.b64decode(encodingData) # Base64 decoding is required because the information of lts logs has been encoded.
text = json.loads(data)
.......
嗯嗯,他们确实只做了base64 !!!! 好吧,从此华为云就从竞品分析的名单消失了。
一通分析下来,我发现需要一个更严谨的针对腾讯云的Event方案,如下:
首先,AWS 的 Gzip+Base64是可取的,但是又不可完全抄。因为AWS的 cloud watch logs 只支持了一些流式单条数据,但是现有的CLS其实是可以批量采集 Nginx 或 Tomcat 这种传统日志的。所以,单条触发函数一定不可取。那么这里只能借鉴其他触发器了增加 batch size 或者 batch window,和研发同学对齐后发现其实 batch window 会更符合聚合场景也更容易实现。所以 CLS 触发器大致的处理流程是这样的:
为保证单次触发传递数据的效率,数据字段的值是 Base64 编码的 ZIP 文档。
{
"clslogs": {
"data": "ewogICAgIm1lc3NhZ2VUeXBlIjogIkRBVEFfTUVTU0FHRSIsCiAgICAib3duZXIiOiAiMTIzNDU2Nzg5MDEyIiwKICAgICJsb2dHcm91cCI6I..."
}
}
用户可在创建触发器时选择聚合事件,触发器组件会自动按照超时时间打包数据,并一次投递多条消息到云函数,当然这个过程是异步的。在解码和解压缩后,日志数据类似以下 JSON 体,以 CLS Logs 消息数据(已解码)为例:
{
"topic_id": "xxxx-xx-xx-xx-yyyyyyyy",
"topic_name": "testname",
"records": [{
"timestamp": "1605578090000000",
"content": "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
}, {
"timestamp": "1605578090000000",
"content": "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
}]
}
这个,是我能想到业内最完美的 CLS 触发器解决方案了,中和了AWS,阿里云的优势,支持Nginx,CDN等多种产品的日志直接聚合投递。用户体验也非常爽,基本只需要三行代码:
const zlib = require('zlib');
exports.main_handler = async (event, context) => {
const payload = Buffer.from(event.clslogs.data, 'base64');
const parsed = JSON.parse(zlib.gunzipSync(payload).toString('utf8'));
console.log('Decoded payload:', JSON.stringify(parsed));
return `Successfully `;
};
这个体验基本可以甩阿里云,华为云20多条街。所以还是那句话,跑得快不是成功,不栽跟头想清楚然后在投入做才是。
哈哈,如上就是一些关于做这个触发器的一些思考,当然后续还有更多。会在得空的时候分享一些心得。同时也给自己备忘。
见解浅薄,如有疏漏还望见谅。最后打个广告:CLB 触发器请看这里! 使用实践请看这里!
切记,切记,切记。做B端产品千万别搞出笑话,华为云真的是。。。。。一言难尽。。。。。