昨天刚刚才开始研究Ckafka To Elasticsearch这个方案,如有不太对的地方还请大佬们指教。首先,我们来介绍下概念和场景部分:
SCF触发器:云函数SCF是典型的事件触发(Event-Triggered)形态的无服务器运行环境,核心组件是 SCF 函数和事件源。其中,事件源是发布事件(Event)的腾讯云服务或用户自定义代码,SCF 函数是事件的处理者,而函数触发器就是管理函数和事件源对应关系的集合。
Kafka: Apache Kafka 消息队列引擎,提供高吞吐性能、高可扩展性的消息队列服务。
Elasticsearch :Elasticsearch Service(ES)是基于开源搜索引擎 Elasticsearch 构建的高可用、可伸缩的云端托管 Elasticsearch 服务。Elasticsearch 是一款分布式的基于 RESTful API 的搜索分析引擎,可以应用于日益增多的海量数据搜索和分析等应用场景。
众所周知,在日志处理场景中最常见的其实是ELK (Elasticsearch、Logstash、Kibana), 腾讯云的Elasticsearch其实已经集成了Elasticsearch、Kibana 那在ELK这个使用场景下缺的应该是一个Logstash的角色,如果可以的话我们为什么不用SCF Ckafka的trigger来替代原有的Logstash呢? 其实原理很简单,在trigger上拉到数据,然后原封不动传给Elasticsearch就可以了。
说干就干,千里之行始于足下,我们先搂一眼 Elasticsearch 的SDK:
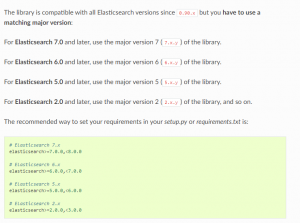
感觉还是比较清爽的,不过这里选择版本的时候必须选择高于当前使用 Elasticsearch 版本的 SDK 否则会报406错误,血的教训。
我这里操作的话使用的 Elasticsearch 7.x 版本的 Python SDK 链接在这里:https://pypi.org/project/elasticsearch7/
Elasticsearch 对SDK的封装特别简单,基本就是对API简单包了一层,其实自己请求 POST 也是可以满足需求的,当然如果自己愿意在去封装的话。。
这里我直接用的 腾讯云基础版本的Elasticsearch服务作为演示,自建也是同理,只要搞对VPC网络就可以了,画个重点这块需要云函数与Elasticsearch同地域同VPC同子网。
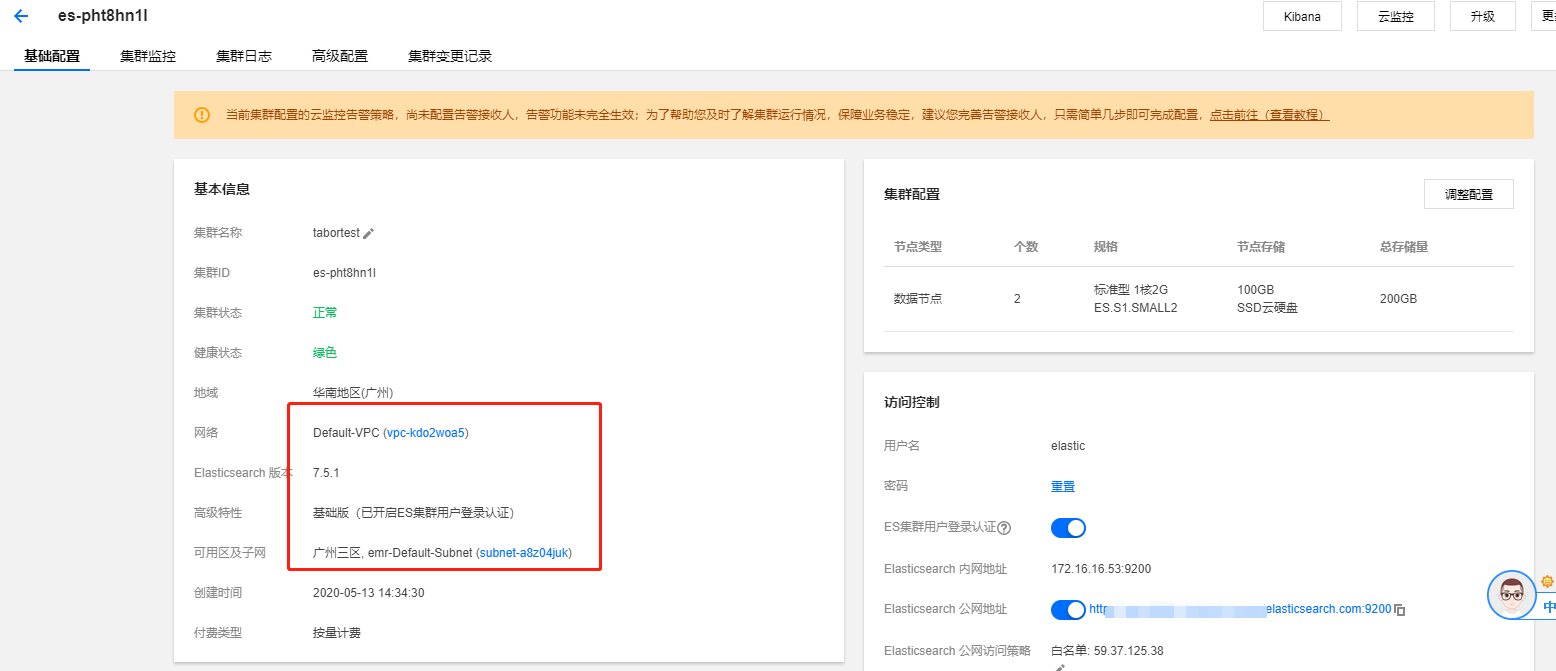
搞完之后我们先看下怎么连接到腾讯云的ES把,腾讯云Es连接需要在Elasticsearch函数的参数中设置如下3个参数关闭节点嗅探:
sniff_on_start=False sniff_on_connection_fail=False sniffer_timeout=None
这里具体应该是这样的,填上自己的es信息就好了,简单的单条插入是这么写的:
from elasticsearch import Elasticsearch
es = Elasticsearch(["http://xx.xx.xx.xx:9200"],
http_auth=('user', 'passwd'),
sniff_on_start=False,
sniff_on_connection_fail=False,
sniffer_timeout=None)
res = es.index(index="my_index", doc_type="my_type", id=1, body={"title": "One", "tags": ["ruby"]})
print(res)
千万注意与云函数同地域,不然这块一定会报错。
事情远远没有那么简单,我们考虑的是ELK海量的处理场景,所以这块直接For循环es.index命令一定没法满足我们的要求,之前实验过顺序向es的my_index索引(该索引已存在)写入100条文档,却花费了大约7秒左右,这种速度在大量数据的时候,肯定不行。
后来,想到一个办法通过elasticsearch模块导入helper,通过helper.bulk来批量处理大量的数据。首先我们将所有的数据定义成字典形式,各字段含义如下:
_index对应索引名称,并且该索引必须存在。
_type对应类型名称。
_source对应的字典内,每一篇文档的字段和值,可有有多个字段。
首先将每一篇文档(组成的字典)都整理成一个大的列表,然后,通过helper.bulk(es, action)将这个列表写入到es对象中。然后,这个程序要执行的话——你就要考虑,这个一千万个元素的列表,是否会把你的内存撑爆(MemoryError)!很可能还没到没到写入es那一步,却因为列表过大导致内存错误而使写入程序崩溃!代码如下:
for i in range(1, 100001, 1000):
action = ({
"_index": "my_index",
"_type": "doc",
"_source": {
"title": k
}
} for k in range(i, i + 1000))
helpers.bulk(es, action)
最后的最后,找到了一个方法,将生成器交给es侧去处理,不在函数处理!这样,Python的压力更小了,不过这里的es压力会更大,无论是分批处理还是使用生成器,es的压力都不小,写入操作本来就耗时嘛:
def Taobrss():
""" 使用生成器批量写入数据 """
action = ({
"_index": "my_index",
"_type": "doc",
"_source": {
"title": i
}
} for i in range(100000))
helpers.bulk(es, action)
那么,得到的demo应该是这样的:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
from datetime import datetime
from elasticsearch import Elasticsearch
from elasticsearch import helpers
esServer = "http://172.16.16.53:9200" # 修改为 es server 地址+端口 E.g. http://172.16.16.53:9200
esUsr = "elastic" # 修改为 es 用户名 E.g. elastic
esPw = "Cc*******" # 修改为 es 密码 E.g. PW2312321321
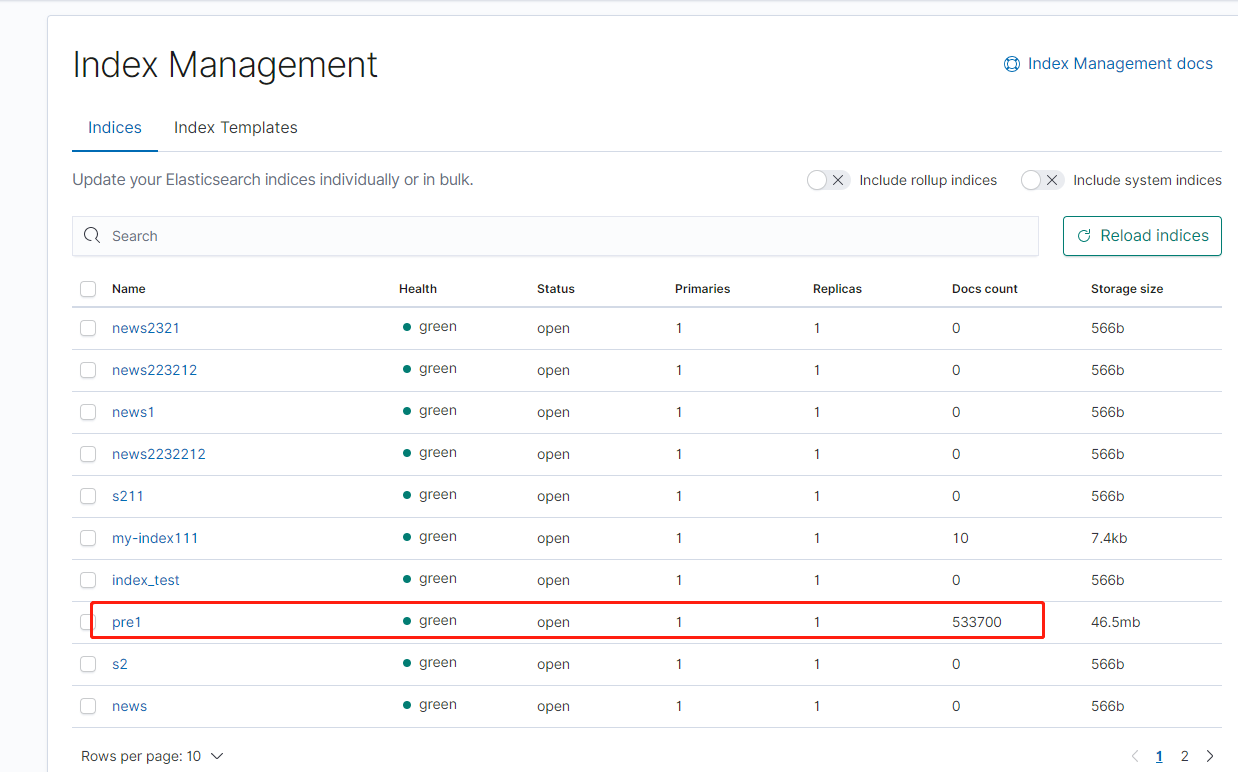
esIndex = "pre1" # es中已经创建的 index ,可以直接通过 es.indices.create(index='my-index111')
# ... or specify common parameters as kwargs
es = Elasticsearch([esServer],
http_auth=(esUsr, esPw),
sniff_on_start=False,
sniff_on_connection_fail=False,
sniffer_timeout=None)
def timer(func):
def wrapper(*args, **kwargs):
start = time.time()
res = func(*args, **kwargs)
print('共耗时约 {:.2f} 秒'.format(time.time() - start))
return res
return wrapper
def main_handler(event, context):
action = ({
"_index": esIndex,
"_source": {
"msgBody": record["Ckafka"]["msgBody"] # 获取 Ckafka 触发器 msgBody
}
} for record in event["Records"]) # 获取 event Records 字段 数据结构 https://cloud.tencent.com/document/product/583/17530
print(action)
helpers.bulk(es, action)
return("successful!")
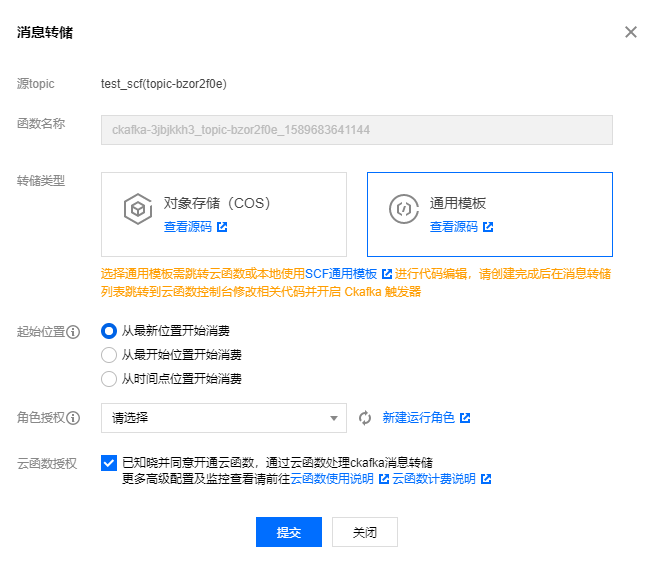
在触发器拿到 event Records 字段 ,搞到ES 完事大吉。触发器这块的设置如下,可以直接在Ckafka消息转储功能中选择通用模板:
CKafka 实例:配置连接的 CKafka 实例,仅支持选择同地域下的实例。
Topic:支持在 CKafka 实例中已经创建的 Topic。
最大批量消息数:在拉取并批量投递给当前云函数时的最大消息数,目前支持最高配置为10000。结合消息大小、写入速度等因素影响,每次触发云函数并投递的消息数量不一定能达到最大值,而是处在1 – 最大消息数之间的一个变动值。
起始位置:触发器消费消息的起始位置,默认从最新位置开始消费。支持最新、最开始、按指定时间点三种配置。
重试次数:函数发生运行错误(含用户代码错误和 Runtime 错误)时的最大重试次数。
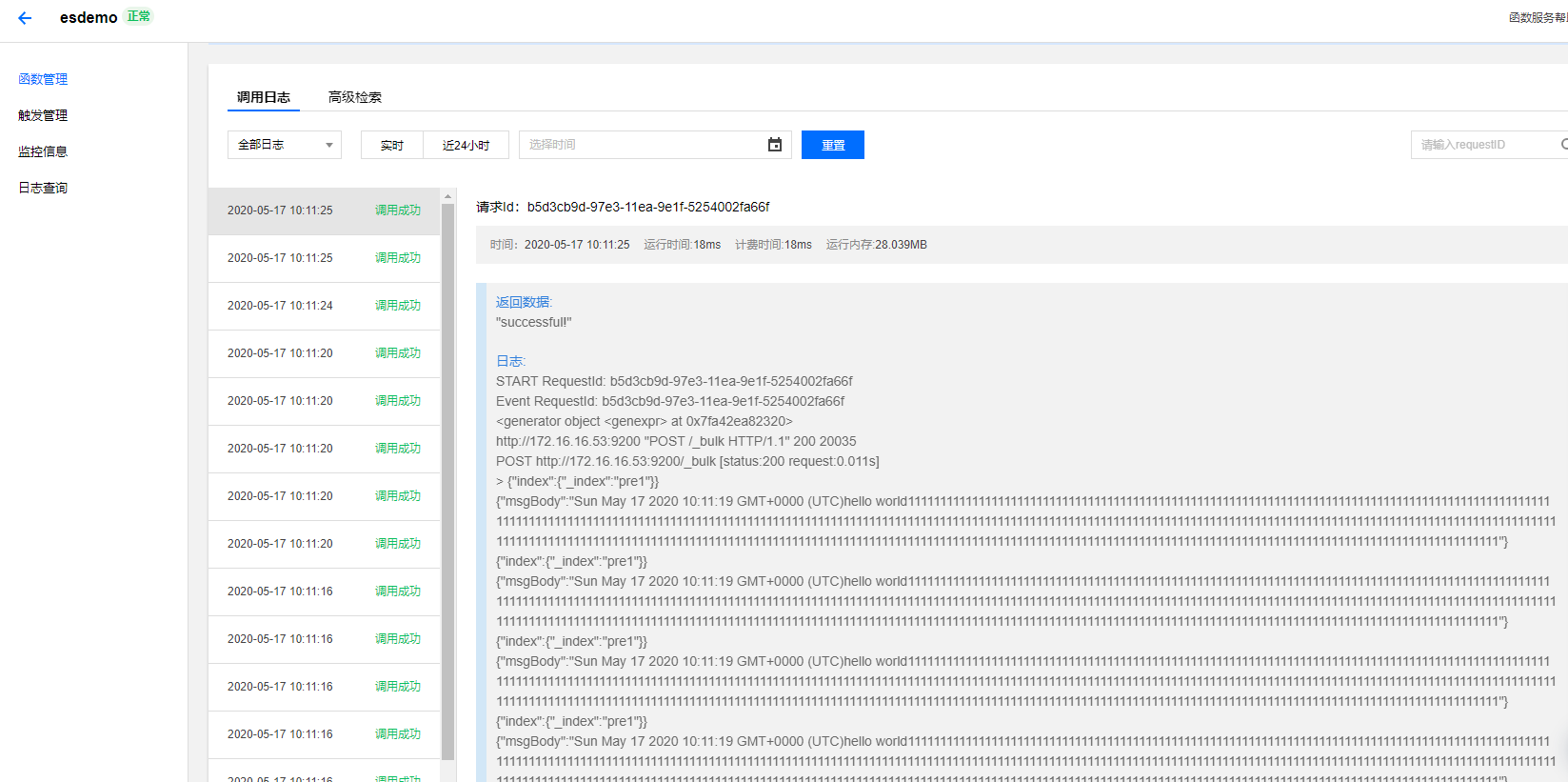
看一眼log和kibana,确认上传信息万事大吉:
代码下载:点击下载