前言
数据湖(Data Lake)概念自2011年被推出后,其概念定位、架构设计和相关技术都得到了飞速发展和众多实践,数据湖也从单一数据存储池概念演进为包括ETL分析,数据转换及数据处理的下一代基础数据平台。
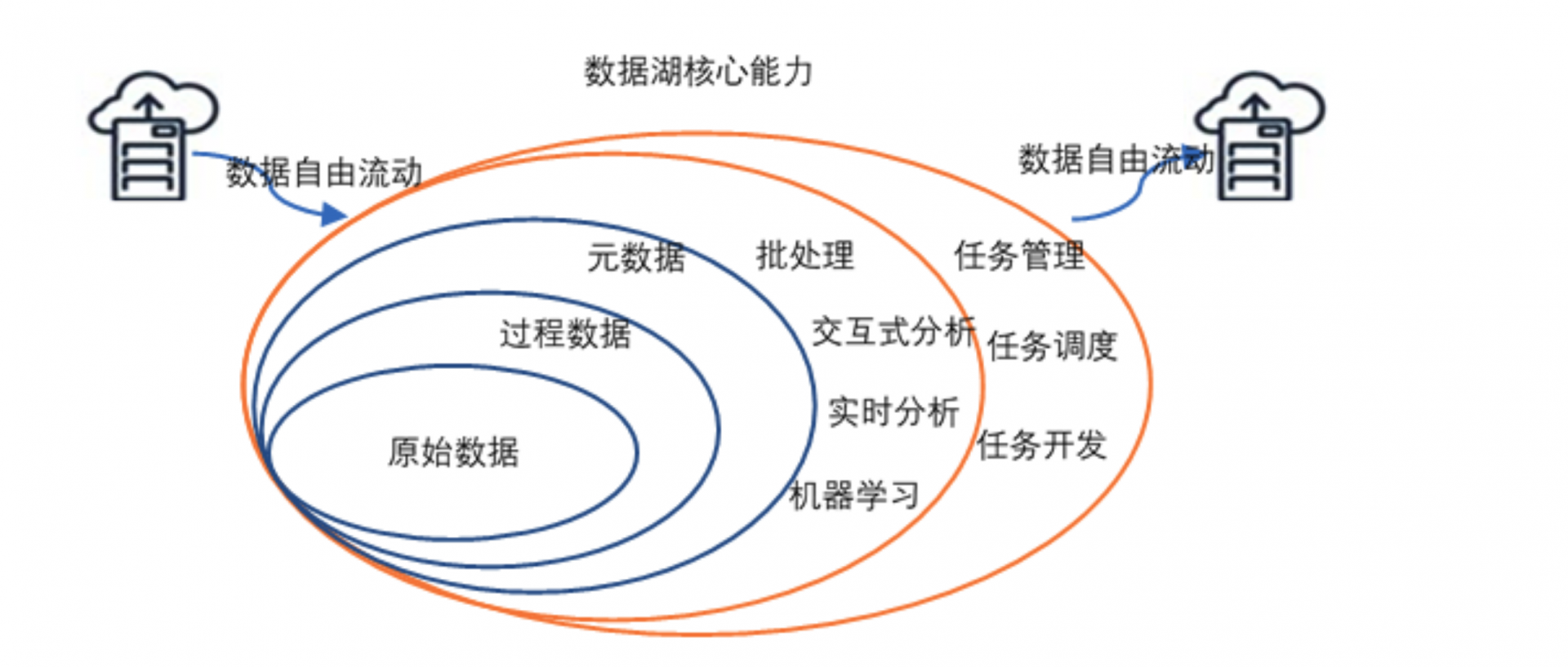
如果需要给数据湖下一个定义,可以定义为这样:数据湖是一个存储企业的各种各样原始数据的大型仓库,其中的数据可供存取、处理、分析及传输。数据湖是一种存储架构,本质上讲是存储,所以,通常情况下会用最经典的对象存储比如 COS (Cloud Object Storage),来当数据湖的地基。
数据湖从企业的多个数据源获取原始数据,并且针对不同的目的,同一份原始数据还可能有多种满足特定内部模型格式的数据副本。因此,数据湖中被处理的数据可能是任意类型的信息,从结构化数据到完全非结构化数据。
那么,企业如何从各个数据源构建数据管道,如何将各种数据数据稳定可靠的存入数据湖存储是非常重要的一环。这篇文章就数据湖的入湖管道为大家详细解答 Serverless 架构下的 COS 数据湖构建方案。
数据湖数据链路分析
为了更好的理解如何构建数据湖,我们可以先了解下数据湖背景下的数据生命周期。
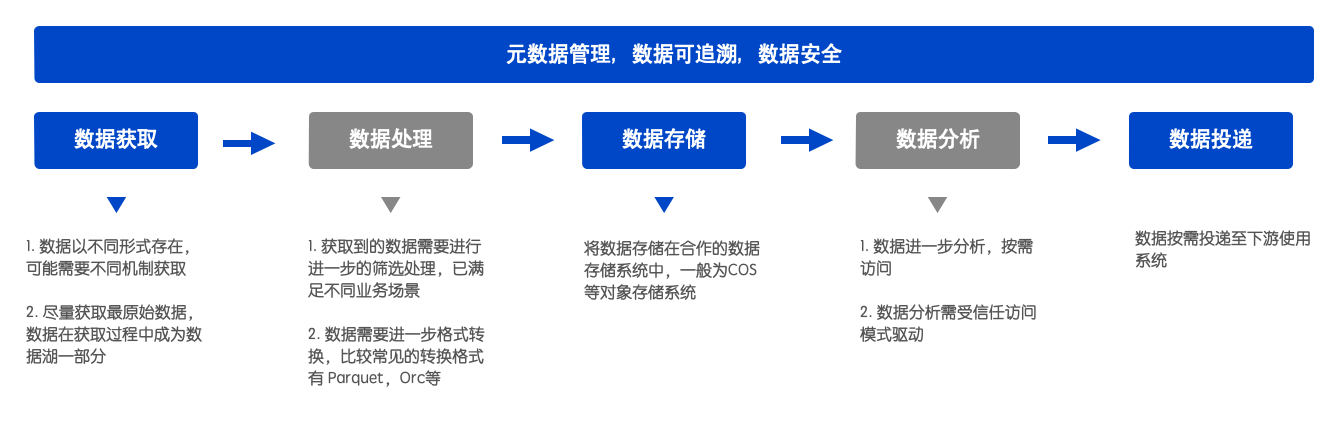
上述生命周期也可称为数据在数据湖中的多个不同阶段。每个阶段所需的数据和分析方法也有所不同。数据处理其实由批量(batch)和流式计算(real – time)两种方式。这里定制化内容会比较多,例如,希望存储数据使用SQL查询访问数据,则上游选择对接必须支持SQL接口,如果希望直接在Kafka拉数据那下游数据获取则需要启 kafka consumer 来拉数据。
传统数据湖架构分入湖与出湖两部分,在上图链路中以数据存储为轴心,数据获取与数据处理其实是入湖部分,数据分析和数据投递其实算是数据出湖部分。
-
入湖部分是整个数据湖架构的数据源头入口,由于数据湖的高便捷可扩展等特性,它需要接入各种数据,包括数据库中的表(关系型或者非关系型)、各种格式的文件(csv、json、文档等)、数据流、ETL工具(Kafka、Logstash、DataX等)转换后的数据、应用API获取的数据(如日志等);
-
出湖部分指的是数据湖的数据接入和数据搜索部分,更偏向数据湖应用。这里场景比较广泛,可以通过各类外部计算引擎,来提供丰富的计算模式支持,比如基于SQL的交互式批处理能力;通过EMR来提供各类基于Spark的计算能力,包括Spark能提供的流计算能力和机器学习能力。
总结来看,整体数据湖链路中定制化程度最高,使用成本及代价最大的其实是数据入湖部分(指数据获取和入湖前的数据处理)。这块内容往往也是实现的数据湖架构比较核心的数据连接。有没有更好的方案来实现对这块的数据链路打通其实是数据湖好不好用的关键节点。
Serverless 架构数据湖解决方案
Serverless 架构湖整体能力点及方案如下图所示,相关解决方案覆盖数据入湖,数据出湖,数据处理 三大能力点,通过 Serverless 化封装为数据入湖,数据出湖提供更多能力拓展。
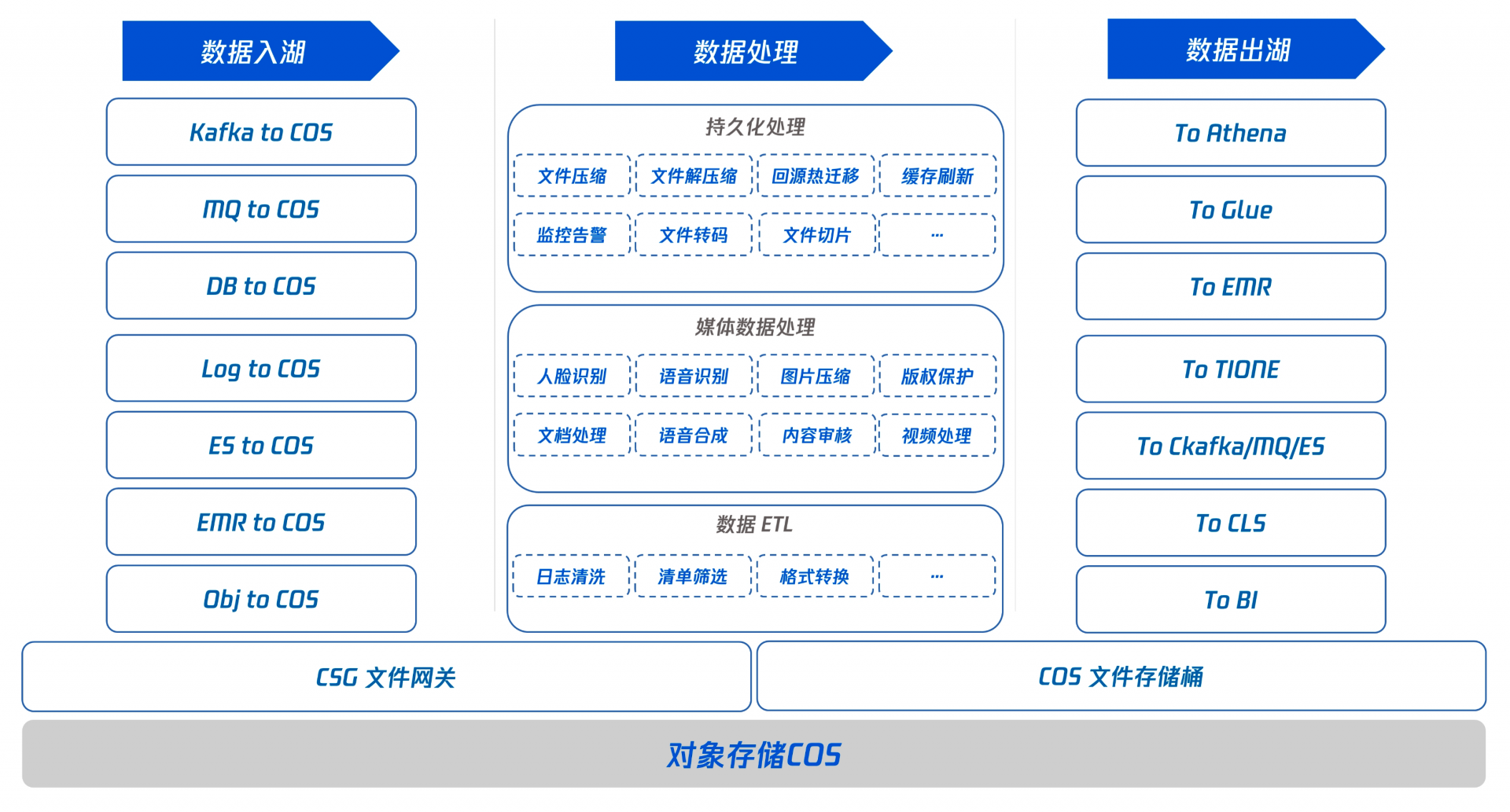
下面以数据湖入湖方案为突破点,为大家详细介绍的 Serverless 架构下的数据湖解决方案。
Serverless 入湖技术架构
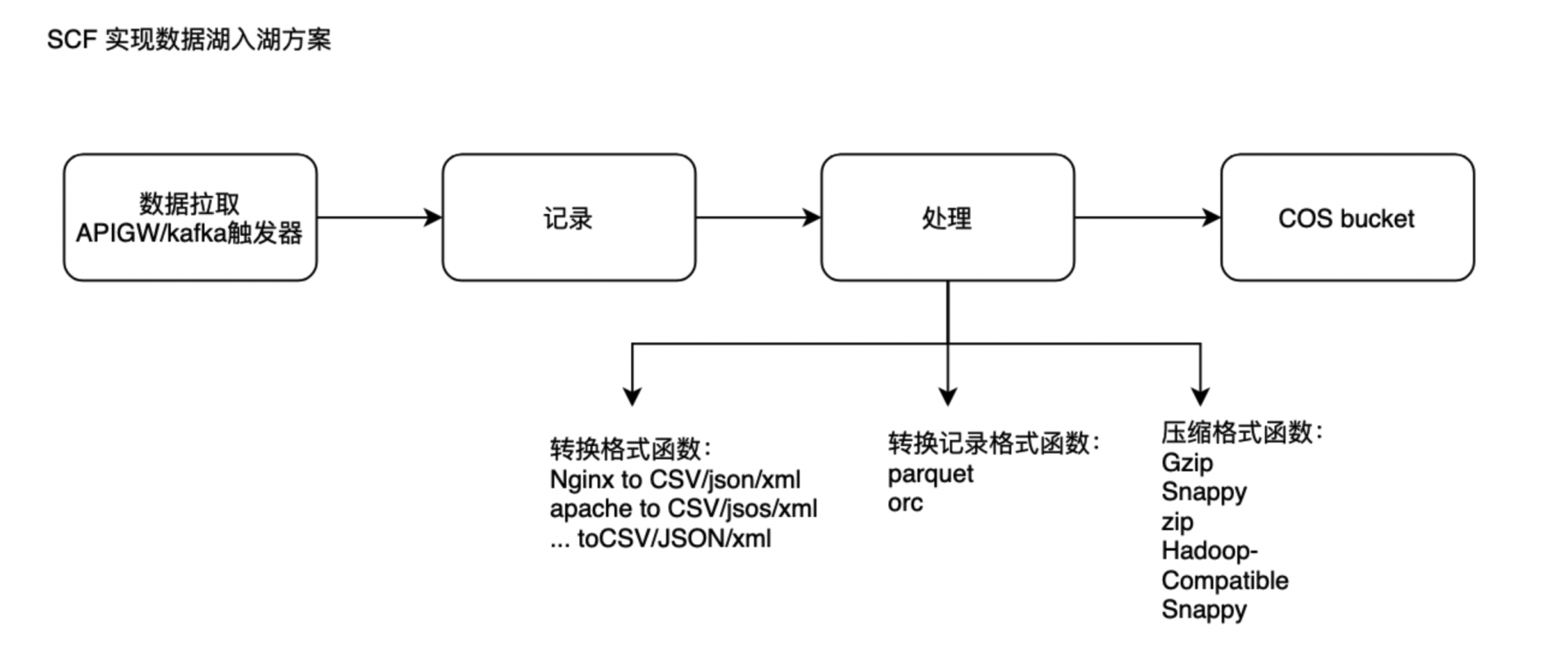
Serverless 架构下的入湖方案其实是 batch 方案,通过云原生的函数触发器或 Cron/APIGW 拉起数据调用,通过函数捕获并记录批次数据信息,在函数内闭环相关的结构转换和数据格式转换,数据压缩等能力。
然后调用 Put Bucket 接口对拉取的数据进行上传,相关架构及处理流程如下图所示:
Serverless 入湖方案优势
-
简单易用,依托 Serverless 计算,数据入湖将提供一键入湖创建,UI 操作即可完成全部入湖逻辑创建。
-
高效,每个入湖模块都是单独运行、单独部署、单独伸缩。提供更加高效的入湖模块逻辑管理。
-
稳定可靠,云函数模块可在发生可用区故障时自动地选择其他可用区的基础设施来运行,免除单可用区运行的故障风险。由事件触发的工作负载可以使用云函数来实现,利用不同云服务满足不同的业务场景和业务需求,使得数据湖架构更加健壮。
-
降低开销,函数在未执行时不产生任何费用,所以对一些无需常驻的业务进程来说,开销将大幅降低。函数执行时按请求数和计算资源的运行时间收费,相比于自建集群部署入湖,价格优势明显。
-
云原生,Serverless 提供更加云原生的入湖解决方案,所有资源云上部署,云上使用,更加便捷高效。
-
可定制,用户可通过模版快速创建通用入湖场景,也可根据自己的业务对数据流进行定制化的 ETL 处理,更方便灵活。
Serverless 入湖方案使用
当前 Serverless 入湖方案已集成在COS 应用集成控制台,可直接访问 https://console.cloud.tencent.com/cos5/application 进行相关能力配置。
![]()
以Ckafka 消息备份为例,点选配置备份规则 – 添加函数 即可进入相关配置页:
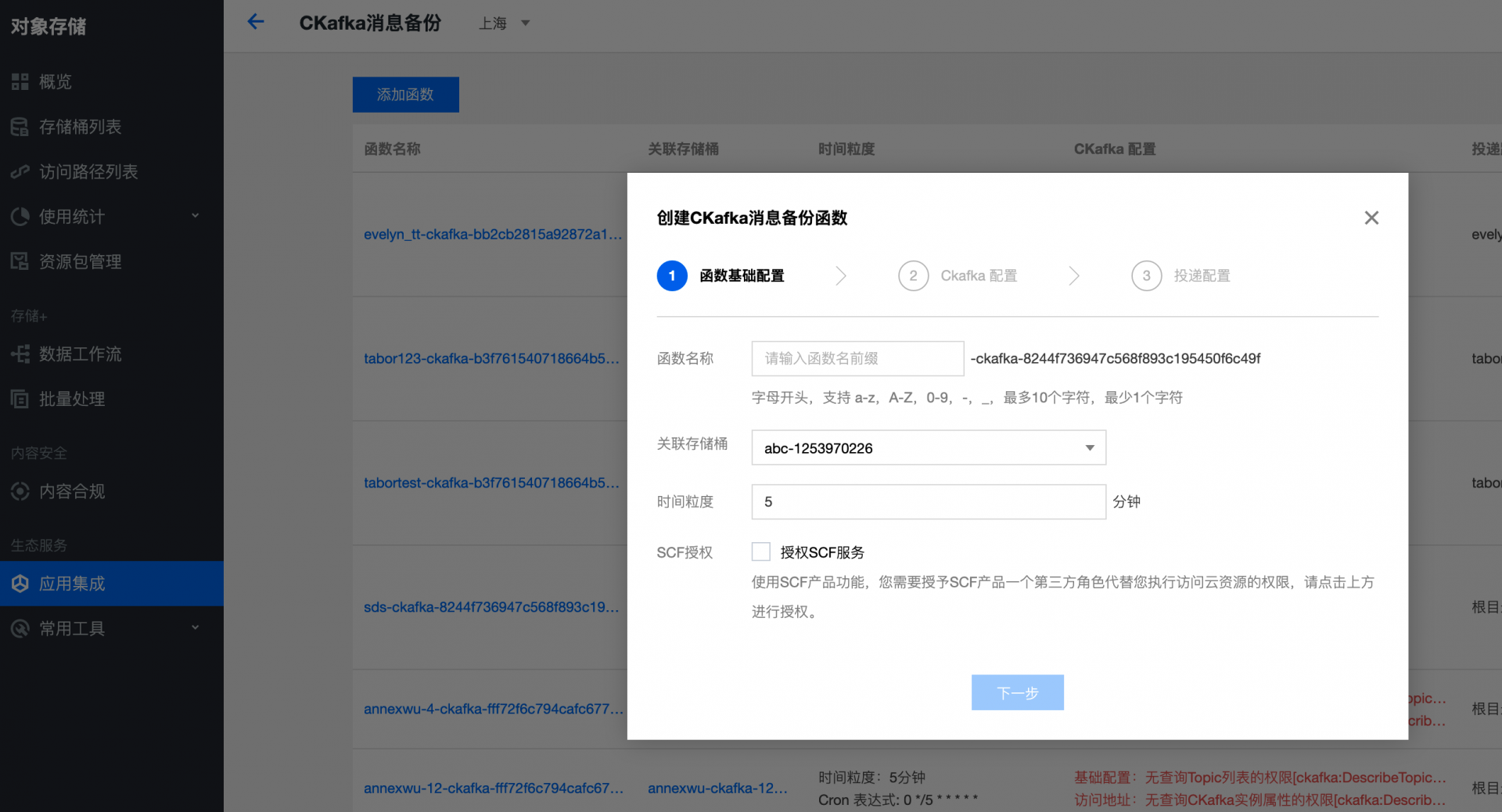
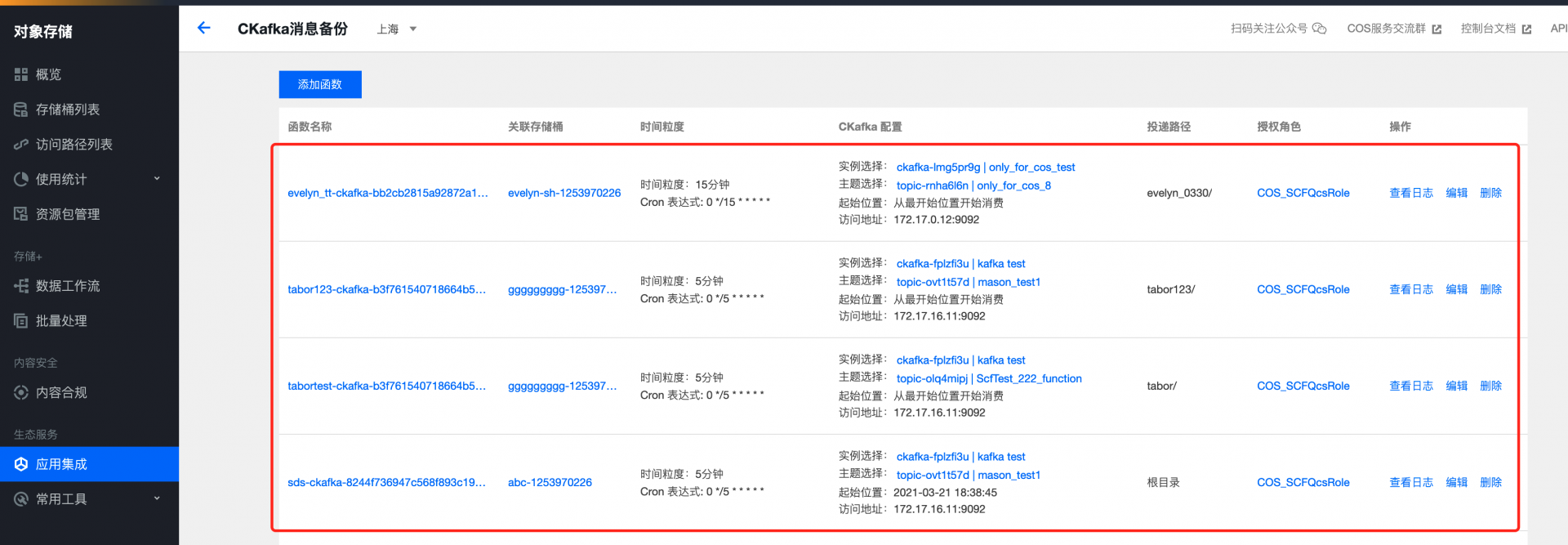
完成配置后可直接在控制台管理相关函数内容:
数据湖方案总结
总的来说 Serverless 体系架构的数据湖方案易用性更高,成本更低,同时通过 Serverless 架构实现数据湖构建方案相对自建集群管理难度更小,数据流转单一,服务治理简单,监控易查询。不过目前数据湖入湖方案全部采用 Batch 架构,相当于 Real-Time 流式计算引擎(Stom,Spark Streaming)来讲,实时性较差。但对大部分企业场景,都能基于统一的数据模型来返回处理结果,对数据处理的影响较小。同时,Serverless 团队同学也在探索关于 Real-Time 框架的更多可能。