经常用FaaS能力的同学肯定遇到过事件重试,目前为止SCF除了两个常见的出口触发器 APIGW/CLB和一个流式kafka同步触发器,大部分触发器其实都是都是异步的。如何保证异步触发器在出现各种报错的情况下合理的被重试和消费是这篇文章探索的主题。为了找到答案,几乎有段时间都是在焦虑中度过的,研发的挑战,客户的挑战,成本的压力,非准大客户完全相悖的使用习惯,几乎能被挑战的点都被我们趟了个遍。功能也马上就上线了,就用这篇日志分享下FaaS场景下,异步队列重试我是如何思考与建设相关能力的吧。
工欲善其事。我们先来讨论下腾讯云云函数在异步调用场景下的常见报错:
第一类 4xx,这里包括400(无效请求),430(用户代码执行错误),432(并发超限),438(函数关停)等等报错
第二类 5xx,这里主要就是500(内部错误),532(计算资源不足)
这么看上去其实很明确,也就两类报错内容。对比,参考友商后第一版的重试策略如下:
4xx错误:帮助用户重试两次,如果配置DLQ(死信队列)后将失败的信息投递至死信队列,如果没有配置DLQ则该事件会直接被丢弃。
5xx错误:考虑5xx一般为系统原因导致错误,故相关事件指数退避重试24小时,24小时后如果还未恢复,该事件将会被丢失。同样DLQ依然对5xx生效。
第一版重试策略沿用了很久,直到云函数将并发上移到用户可配置后,矛盾点爆发了。
首先,是对默认4xx重试两次的挑战,有的用户明确表示自己不希望做任何重试。这点很好解决,我们将默认4xx重试的次数交给用户,用户可以从 0-2 中任意选择所需的重试次数。
其次,是对SLA的挑战,在之前的重试队列是没有任何淘汰机制的,打个比方如果用户将保留配额(reserved concurrency)放到 0 ,并且在异步队列中塞进 100条事件内容。在之前的策略中,该100条事件将永远无法被消费,甚至成为永久的脏数据。所以我们需要一个统一的淘汰机制来保证队列消息不会被用户行为打爆。这里我们将异步队列设置一个时间长度,以最大6小时为限,超过6小时的事件将直接被丢弃,如果配置DLQ,会将相关消息投递至DLQ。
看起来这两个策略是完美的了,至少它可以解决我们现在的用户问题。但,这仅仅完成了最简单的部分。
我们都知道异步队列最大的作用其实是保证用户缓冲某个时刻大量的高并发数据。之前并发都是和 work match的,并发上移后启多少work就变成了一个很玄学的事情,打个最简单的比方,下图是我们经常会遇到的情况并发超限。并发超限按照第一版的重试策略会跟随全部4xx,重试两次后丢弃。
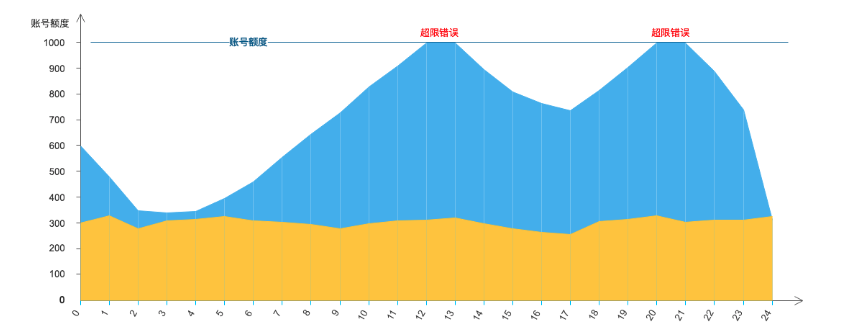
什么?数据丢失?并发配额上线那段时间几乎每天都有在抱怨丢数据。这在完全托管的异步队列是完全不能出现的情况,比较理想的状态就是用户有多少并发就启多少 work,这样超限错误永远就不会存在了。如下图
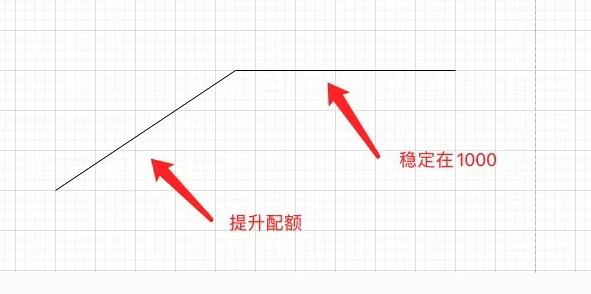
但是的但是,这里基本是不可能实现的,或者实现起来难度非常大,对资源调度的管理要求太高。那又有什么办法可以保证用户的数据不丢失呢?我几乎想尽了所有办法,还是AWS给了我灵感,如下是AWS并发超限时 Throttles 的监控图:
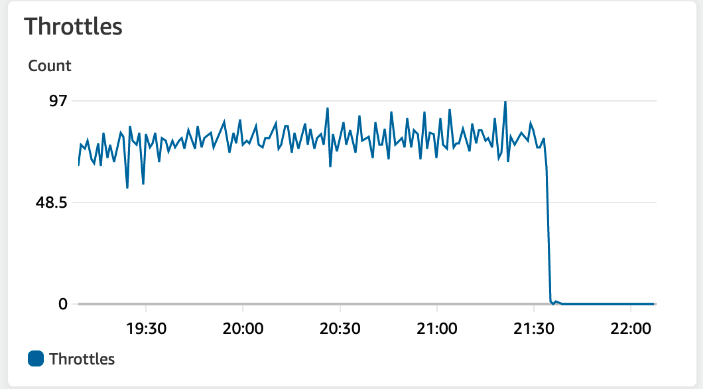
我恍然大悟,这块也是重试策略的能力啊,我们为什么不把超限错误重新投回队列进行重试呢?这样不久完美解决了超限数据丢失?其实根本不需要什么复杂的算法来解决超限啊。所以,最新的重试是这样的:
运行错误(含用户代码运行错误和 Runtime 错误):当发生该类错误时,函数平台将默认重试两次或使用配置的重试次数,固定间隔1分钟。在自动重试的同时,新的触发事件仍可正常处理。如果您配置了死信队列,重试两次失败后的事件将传入死信队列,否则事件将被函数平台丢弃。
系统错误:当发生该类错误时,函数平台会根据您配置的最长等待时间持续重试(默认持续重试6小时),重试间隔按照指数退避增加到5分钟。如果您配置了死信队列,重试超过最长等待时间仍失败的事件会被发送到死信队列,由用户进行进一步处理,否则事件将被函数平台丢弃。
超限错误:当发生该类错误时,函数平台会根据您配置的最长等待时间持续重试(默认持续重试6小时),重试间隔为1分钟。如果您配置了死信队列,重试超过最长等待时间仍失败的事件会被发送到死信队列,由用户进行进一步处理,否则事件将被函数平台丢弃。
调用请求错误和调用方错误:当发生该类错误时,平台将不会对该类其他错误进行重试,因为其他请求错误即便重试也不会成功。(超限错误(432)除外)
新版的重试完美解决了并发超限给用户带来的丢数据的风险,也让异步队列发挥了它应有的价值。异步调用的并发超限用户再也无需进行任何操作,在设定的最长等待时间内,函数平台会自动对并发超限错误进行重试。
这个探索的过程相当煎熬,也几乎和研发同学PK了无数轮。好在最后我们完成了目标,当然是在经过两轮的方案推倒重做后。当然也在探索这里关于更开放的错误码重试策略的事情,但总感觉为时过早还需要论证和调研,所以这里就不介绍了。
总结一些思路,寥寥数语,如有偏颇还请谅解。